


 |
 |
||||||||||
 |
Come si fa ricerca in Internet
Internet, abbiamo detto più volte, costituisce una immensa risorsa informativa. Già a metà degli anni '90, quando i territori del Web (assai meno sconfinati di oggi) erano esplorati solo da pochi pionieri, la bacheca di una facoltà universitaria italiana ospitava un avviso dal titolo singolare: "Cercatore d'oro offresi". Non si trattava della vendita di un cercametalli, ma dello slogan scelto da un giovane e intraprendente cibernauta per offrire - a prezzi popolari - i suoi servigi di information broker via Internet. L'oro, dunque, era l'informazione, e il nostro cercatore garantiva di poter reperire, in rete, informazione per tutte le esigenze: dallo studio per un esame alla preparazione di una tesi di laurea, dalla ricerca giornalistica alla semplice curiosità. Affermazioni all'epoca sorprendenti, diventate banali in meno di una decina di anni. Il problema - anzi - è oggi spesso l'opposto, ed è ben noto a chiunque si trovi a operare nei settori della didattica e della ricerca: ricordarsi - e ricordare - che Internet non è (o non è ancora) il deposito universale della conoscenza umana, nel quale trovare risposta a qualsiasi domanda. Sempre più spesso ci si trova davanti a ricerche scolastiche, tesi di laurea, articoli scientifici realizzati basandosi unicamente sul materiale reperibile attraverso Internet. E spesso questo materiale è frutto di ricerche incomplete, incompetenti o imprecise, che denunciano limiti evidenti sia nella capacità di reperimento, sia nella valutazione e selezione dell'informazione. Prima di fornire indicazioni su come svolgere ricerche in rete con una migliore e più consapevole scelta di strumenti e strategie - giacché questo sarà l'obiettivo delle pagine che seguono - conviene dunque ribadire che chi sapesse avviare una ricerca in rete ma non sapesse poi proseguirla (e integrarla) in una biblioteca, in un archivio, in un museo, sarebbe ben povero cercatore. Il mondo della conoscenza non si esaurisce nelle pagine del Web, anche se il Web può essere - per chi sa utilizzarlo, valutando e selezionando le proprie fonti - un fenomenale strumento di conoscenza. Per essere ancor più espliciti, è nostra convinzione che il vero 'virtuoso' nel campo della ricerca, gestione e produzione dell'informazione, l'information manager del terzo millennio, sia chi riesce a meglio padroneggiare e integrare fonti informative diverse, tradizionali e no. Se il 'cercatore d'oro' dell'annuncio appena citato avesse davvero questa capacità, le sue pretese sarebbero pienamente giustificate, e il suo futuro economico sarebbe probabilmente assicurato. Farsi una vaga idea di come funzioni una biblioteca è abbastanza facile, ma saper usare bene una biblioteca non lo è affatto. Lo stesso discorso vale per Internet. Chi pensasse che, grazie alla disponibilità di motori di ricerca ai quali proporre parole chiave da trovare, reperire informazione su Internet sia relativamente semplice, commetterebbe di nuovo un grave errore di valutazione. Internet mette a disposizione informazione di natura assai eterogenea, raggiungibile attraverso canali diversi. Per svolgere correttamente una ricerca occorre per prima cosa interrogarsi sulla natura dell'informazione che stiamo ricercando, e avere la capacità di capire se, dove e attraverso quali strumenti essa può essere reperita su Internet. L'information broker su Internet deve dunque conoscere abbastanza bene la rete; ma, soprattutto, deve aver piena coscienza della diversa natura di molte fra le fonti informative accessibili attraverso di essa. Alcuni concetti di baseInformazione ordinata e informazione disordinataSupponiamo, ad esempio, di dover svolgere una ricerca sulla musica per liuto. Il tema sembra abbastanza specifico e circoscritto. Ma è veramente così? Consideriamo i tipi diversi di informazione che potremmo voler trovare:
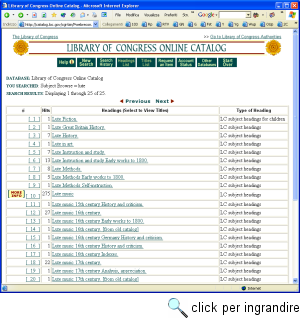
Sicuramente non si tratta di un elenco completo, ma dovrebbe bastare a illustrare un concetto essenziale: per svolgere correttamente una ricerca non basta conoscerne l'argomento - sapere cioè su che cosa vogliamo trovare informazione. Bisogna anche sapere che tipo di informazione vogliamo trovare. Questo naturalmente è vero in generale, ed è particolarmente vero nel caso di ricerche svolte attraverso Internet. La rete ci può aiutare nella maggior parte dei compiti elencati sopra (e forse addirittura in tutti). Ma non possiamo pensare di cercare in un unico posto, o di usare un unico strumento di ricerca. In particolare, nel cercare informazione in rete va tenuta presente la differenza fondamentale fra informazione fortemente strutturata e informazione 'libera', non strutturata e a volte occasionale. Per capire meglio la natura di questa differenza, consideriamo il secondo dei compiti sopra elencati: raccogliere una bibliografia sul liuto e la musica per liuto. Naturalmente, la costruzione di una bibliografia ragionata è un compito che richiede non solo la consultazione di cataloghi e repertori, ma anche lo studio diretto di almeno parte dei testi selezionati. Limitiamoci però al primo livello, quello della mera raccolta di informazioni bibliografiche essenziali. Un buon punto di partenza può essere, evidentemente, il catalogo di una biblioteca. Attraverso Internet se ne possono raggiungere moltissimi (come vedremo fra breve, i cataloghi di biblioteca accessibili on-line vengono denominati OPAC: On-line Public Access Catalog); supponiamo di partire dal catalogo della Library of Congress, all'indirizzo http://catalog.loc.gov/. La consultazione del catalogo non è difficile, e ci si può far guidare dalle schermate di aiuto. Nel caso specifico, una ricerca per soggetto con chiave 'lute', svolta sul catalogo principale, ci porta a un lungo elenco di voci, ciascuna delle quali accompagnata dal numero di titoli classificati sotto di essa. Fra le voci segnalate spicca - nella seconda pagina di risultati (figura 61), raggiungibile attraverso il link 'Next' - il soggetto 'lute music', che comprende da solo ben 275 titoli. Nel complesso, nell'aprile 2003 figurano nel catalogo 87 voci di soggetto connesse al liuto, attraverso le quali è possibile accedere alle schede bibliografiche di 724 titoli: libri o spartiti musicali disponibili in biblioteca e classificati come pertinenti al liuto o alla musica per liuto.
Naturalmente, oltre alla Library of Congress potrei consultare i cataloghi di numerose altre biblioteche: ad esempio la British Library (http://blpc.bl.uk/), o la Bibliothèque Nationale di Parigi (http://catalogue.bnf.fr/; ovviamente, in questo caso la ricerca andrà fatta sul termine francese 'luth') o, in Italia, il catalogo del Servizio Bibliotecario Nazionale (SBN) raggiungibile alla URL http://opac.sbn.it/. Una ricerca di questo tipo ci porta, in un'ora circa di lavoro dalla scrivania di casa, a consultare i cataloghi di molte fra le maggiori biblioteche mondiali (magari anche attraverso i cosiddetti meta-OPAC: siti in rete che permettono di interrogare insieme, attraverso un'unica ricerca, i cataloghi di più biblioteche: ne parleremo in seguito), e a raccogliere (abbiamo fatto la prova) una bibliografia di circa mille titoli. Internet, dunque, si è rivelato uno strumento di ricerca prezioso. Ma in questo momento ci interessa soffermarci soprattutto sul tipo di informazione che abbiamo cercato. Il catalogo informatizzato di una biblioteca è una raccolta ordinata di informazioni, che è possibile consultare attraverso una interfaccia standard, e su cui è possibile effettuare ricerche attraverso un linguaggio di interrogazione. Quando facciamo una ricerca di questo tipo, sappiamo in anticipo che tipo di informazione ci verrà restituita: se la ricerca ha esito positivo, ne ricaveremo un certo numero di schede bibliografiche, con una struttura costante (autore, titolo, luogo e anno di edizione, numero delle pagine, formato, collocazione...). Attenzione: il catalogo di una biblioteca contiene schede di libri, non direttamente i libri. Sembra una informazione ovvia, ma è sorprendente il numero di persone che arrivate al risultato di una ricerca bibliografica in rete chiedono 'ma il libro, da Internet, non si può leggere? E allora tutto questo a cosa serve?'. No, il libro di norma non è in rete: il catalogo di una biblioteca raccoglie informazioni sui libri, i libri fisici stanno negli scaffali. Lo stesso vale per Internet: solo in alcuni casi, come vedremo, si è fatto il passo ulteriore (estremamente più complesso e oneroso) di inserire in rete il testo completo di una selezione di libri. E - anche se i progetti di questo tipo (le cosiddette digital libraries) sono in continuo sviluppo (ne parleremo in dettaglio nel capitolo dedicato alle biblioteche in rete), e si tratta di un settore dal quale potremo aspettarci molte sorprese nei prossimi anni - lo si è fatto finora principalmente per le grandi opere delle letterature nazionali, i cosiddetti 'classici', non certo per testi di riferimento sulla musica per liuto. Ma su questo torneremo. L'utilità di un catalogo in rete, allora, dov'è? Ebbene, se questo è il vostro interrogativo, dovete fare ancora parecchia strada per diventare 'professionisti' della ricerca, su Internet o fuori da Internet. Sapere quali libri è possibile consultare su un determinato argomento, e dove reperirli, è un primo passo fondamentale. Ed è un passo che fino a una decina di anni fa poteva richiedere molto, moltissimo tempo. Internet modifica radicalmente questa fase della ricerca. Certo, una (grossa) parte del lavoro andrà poi fatta nel mondo fisico, consultando libri reali. Chi pensasse di poter buttar via la propria tessera della biblioteca per il fatto di avere accesso a Internet, sbaglierebbe quindi di grosso. Intendiamoci: nel medio e lungo periodo in rete saranno senz'altro disponibili collezioni sempre più vaste di testi elettronici completi. Col tempo, libri e biblioteche cambieranno forma (anche se - per fortuna - continueranno comunque a esistere). Ma la situazione attuale è questa: Internet fornisce un grosso aiuto per trovare informazioni bibliografiche, ma di norma non consente l'accesso diretto al testo dei libri di cui abbiamo reperito i dati. Ma torniamo alle nostre schede di libri, ai nostri dati catalografici. Sono utili, utilissimi, e sappiamo (o dovremmo sapere) come usarli. Ma nella nostra ricerca sulla musica per liuto, Internet non ci offre nient'altro? Ebbene, anche in questo caso tutto dipende da che tipo di informazione stiamo cercando. Nessuno userebbe il catalogo di una biblioteca per cercare l'immagine di un liuto, o per acquistare un disco di musica per liuto, anche se naturalmente alcuni dei libri presenti a catalogo potrebbero fornirci informazioni utili al riguardo, e la ricerca sul catalogo potrebbe essere utile per trovare quei libri. D'altro canto, il ricercatore accorto (ma non sempre quello occasionale) sa che una ricerca come quella che abbiamo proposto poc'anzi sul catalogo della Library of Congress fornisce per lo più titoli di libri, e non titoli, ad esempio, di articoli su riviste; e sa che le riviste specializzate possono essere anch'esse una fonte informativa essenziale (cosa pensereste della bibliografia di una tesi di laurea che citasse solo libri, e nessun articolo?). Nessun timore: attraverso Internet - come vedremo - si possono fare ricerche anche su basi dati costituite da abstract di articoli (anche se questo genere di risorse è sempre più spesso a pagamento). Quello che ci preme sottolineare in questa sede, tuttavia, è che per fare una ricerca non basta la mera competenza 'tecnica': occorre sapere cosa stiamo cercando, e avere delle buone strategie di ricerca. Attraverso Internet sono dunque accessibili - fra le altre cose - banche dati specializzate, contenenti informazione fortemente strutturata, come il catalogo di una biblioteca (ma anche banche dati di formule chimiche, o di genetica, o di mappe geografiche, o di informazioni sociopolitiche sui vari stati mondiali, o atlanti stellari...). Non ci capiteremo per caso: le consulteremo quando cerchiamo informazioni di quel tipo. E - occorre che questo sia ben chiaro - il contenuto di una di queste banche dati è accessibile attraverso Internet, ma non nello stesso senso in cui lo è, ad esempio, una pagina Web: se utilizzassimo uno dei cosiddetti 'motori di ricerca' che indicizzano le informazioni presenti su Web, non arriveremmo mai dentro al catalogo di una biblioteca (a meno, naturalmente, che il catalogo stesso non sia interamente costruito utilizzando pagine HTML). Per capire la ragione di questo fatto - che sconcerta talvolta gli utenti alle prime armi - occorre tener presente che, anche se quasi tutti i cataloghi on-line forniscono il risultato delle nostre ricerche sotto forma di pagine Web, queste pagine Web non esistono prima della ricerca stessa. Infatti, esse sono generate 'al volo' dal server in risposta alla nostra interrogazione, e non sono dunque conservate su un file permanente. Ciò significa che i motori di ricerca non possono raggiungerle e indicizzarle (sarebbe del resto ovviamente impossibile indicizzare i risultati di tutte le innumerevoli ricerche possibili su una base dati catalografica). Consideriamo adesso gli altri tipi di ricerca concernenti il liuto che avevamo suggerito come esempio: in molti di questi casi non ricorreremo a banche dati altamente strutturate come il catalogo di una biblioteca, ma all'informazione sparsa disponibile in rete. Cosa vuol dire 'informazione sparsa disponibile in rete'? Vuol dire che qualcuno - una istituzione musicale, un appassionato, un negozio di musica - ha ritenuto di rendere accessibili (spesso attraverso pagine Web, ma talvolta attraverso appositi database, come accade ad esempio nella maggior parte dei siti di commercio elettronico) informazioni da lui considerate interessanti o utili. Nel caso del catalogo di una biblioteca, sapevamo già cosa aspettarci. In questo caso, non lo sappiamo. Troveremo immagini di liuti? Sicuramente. Troveremo immagini di un tipo particolare di liuto? Probabilmente sì, ma non ne siamo sicuri. E che affidabilità avranno le notizie che raccoglieremo? Impossibile dirlo a priori: un negozio di strumenti musicali potrebbe avere interesse a parlar bene di una certa marca di strumenti perché deve venderli; un appassionato potrebbe avere una sensibilità musicale diversissima dalla nostra. In poche parole, anziché una informazione fortemente strutturata, in genere avalutativa e uniformemente caratterizzata da un alto livello di affidabilità, stiamo cercando (e troveremo) una informazione assai più eterogenea. Non per questo - si badi - il risultato della nostra ricerca sarà meno utile o interessante: sarà solo di diversa natura. Va anche considerato che qualunque ricerca su World Wide Web è fortemente legata al momento in cui viene fatta: l'evoluzione della rete è infatti continua, e questo significa non solo che nuova informazione viene aggiunta ogni giorno, ma anche che alcune informazioni possono essere rimosse, o spostate. Abbiamo potuto accorgercene direttamente verificando, edizione dopo edizione di questo manuale, quali e quanti cambiamenti vi fossero nei risultati di una ricerca quale quella che abbiamo scelto a mo' di esempio. Nello scrivere questa sezione del manuale, nel caso di Internet '96 eravamo partiti da quello che era all'epoca il principale motore di ricerca per termini: AltaVista, della Digital. La ricerca era stata effettuata sul termine 'lute' (naturalmente, nel caso di Internet la prima ricerca viene in genere fatta utilizzando il termine inglese; una ricerca più raffinata vi avrebbe affiancato almeno i corrispondenti termini italiani, francesi, tedeschi, spagnoli...). Ebbene, se nel marzo 1996 questa ricerca aveva fornito un elenco di circa 5.000 pagine nelle quali compare, per i motivi più vari, la voce 'lute', effettuando la stessa ricerca nel marzo 1997 le pagine disponibili sono risultate oltre 8.000, nel marzo 1998 erano oltre 34.000, nel settembre 1999 erano diventate più di 51.000, e nell'aprile 2003 (usando quello che come vedremo è oggi il leader indiscusso dei motori di ricerca per termini, ovvero Google) avevano raggiunto la cifra davvero ragguardevole di 316.000: una testimonianza impressionante della continua crescita del Web, una crescita che prosegue inarrestabile e non sembra toccata più di tanto dalla crisi della new economy. Tenete presente, peraltro, che proprio per il numero decisamente poco governabile di occorrenze che ci vengono fornite, in casi come questo una ricerca per termini su un motore di ricerca come Google potrebbe non essere sempre la strada migliore per trovare cosa c'è in rete sulla musica per liuto. Ma su questo torneremo. Naturalmente, quello del liuto è solo un esempio fra gli innumerevoli che si potrebbero fare. Il nostro scopo principale era quello di far comprendere l'esistenza di differenze notevolissime nella tipologia dell'informazione raggiungibile attraverso la rete. Imparare come e dove cercare tipi di informazione diversa costituisce un primo passo essenziale per padroneggiare - per quanto possibile - l'offerta informativa di Internet. Forniremo, nel seguito, altri esempi e suggerimenti, anche se il lettore deve essere consapevole che in questo campo nessuna istruzione e nessun consiglio possono sostituire l'esperienza e, perché no, anche il 'fiuto' che possono venire solo dalla pratica della ricerca attraverso la rete. Dall'ordine al disordine, dal disordine all'ordineAncora qualche breve considerazione generale. Abbiamo ricordato la differenza fra informazione 'ordinata' e informazione 'disordinata', e abbiamo visto che entrambe presentano vantaggi e difficoltà. L'informazione 'ordinata' di una banca dati è in genere più puntuale e affidabile, ma, pur essendo raggiungibile attraverso Internet, non è in genere integrata nella grande ragnatela ipertestuale del Web. L'informazione 'disordinata' disponibile sotto forma di pagine Web è più difficile da valutare dal punto di vista dell'affidabilità, e per reperirla siamo spesso costretti a navigazioni che possono sembrare quasi casuali, e talvolta frustranti. Questa situazione spiega quelli che sono forse i compiti principali che una fonte di risorse informativa come Internet, in crescita talmente rapida da non potersi permettere 'pause di riflessione' per la riorganizzazione del materiale disponibile, si trova a dover affrontare: integrare e organizzare l'informazione fornita. Internet, tuttavia - a differenza di quanto vorrebbe far credere un certo numero di film 'alla moda' sulla nuova realtà delle reti telematiche - non è una sorta di 'superorganismo' autocosciente. L'integrazione e l'organizzazione delle informazioni disponibili in rete dipende in gran parte dai suoi utenti 'di punta': in primo luogo da chi fornisce informazione e da chi progetta, realizza e rende disponibili programmi e motori di ricerca. Organizzare l'informazione: ipertesti e metainformazione descrittivaIl tentativo di capire come integrare e organizzare l'informazione disponibile in rete rappresenta uno dei principali fattori che hanno determinato lo sviluppo di Internet (e in particolare del Web) negli ultimi anni, e sarà senz'altro fra i nodi teorici principali che resteranno al centro dell'evoluzione della rete nel prossimo futuro. Dal punto di vista dei fornitori dell'informazione, questo impegno si traduce da un lato nel tentativo di comprendere al meglio i meccanismi di funzionamento 'concettuale' di un ipertesto, in modo da realizzare ipertesti fruibili e funzionali, dall'altro nello studio delle strategie migliori per associare in maniera utile e pertinente all'informazione disponibile all'interno delle proprie pagine anche l'opportuna metainformazione descrittiva. Entrambi i compiti non sono affatto facili. Cerchiamo di capire meglio di cosa si tratta, e perché la buona organizzazione ipertestuale e la disponibilità di metainformazione adeguata siano così importanti per la reperibilità e l'efficacia informativa di un sito. Cominciamo dal problema della struttura ipertestuale. Basta infatti un minimo di esperienza di navigazione su Web per rendersi conto che, se stabilire qualche collegamento all'interno delle proprie pagine, e fra esse e il mondo esterno, basta a costruire formalmente un ipertesto, perché questa costruzione sia adeguata dal punto di vista semantico, produttiva dal punto di vista informativo e funzionale dal punto di vista operativo, serve molto di più. Parlando di World Wide Web abbiamo visto come alla sua radice vi sia l'idea di una struttura ipertestuale, e come la linea di tendenza chiaramente percepibile sia quella dell'assorbimento all'interno della struttura ipertestuale del Web anche delle altre funzionalità di Internet. Programmi di gestione della posta elettronica o di lettura dei newsgroup Usenet capaci di attivare automaticamente un browser, filmati e file musicali resi accessibili partendo da una pagina Web, disponibilità di accessori e plug-in in grado di visualizzare direttamente nel browser file e documenti prodotti dai programmi più vari, ne sono eloquente testimonianza. I percorsi disponibili - sotto forma di link, di collegamenti da una informazione all'altra - all'interno di questa sterminata mole di informazioni sono fili che aiutano a camminare attraverso un labirinto. Se questi fili guidano lungo itinerari inconsistenti, portano a movimenti circolari, ci distraggono dalle risorse che effettivamente cerchiamo o le presentano in modo fuorviante o disordinato, la navigazione risulterà difficile o infruttuosa. Supponiamo, ad esempio, di voler realizzare una rivista letteraria in rete. Entusiasti per le possibilità offerte dalla strutturazione ipertestuale dell'informazione, ci ingegnamo nel trovare il maggior numero possibile di collegamenti fra il materiale da noi fornito e il resto delle risorse disponibili. Ci viene proposto un articolo su Goethe, e noi lo 'pubblichiamo' integrandolo con quello che - riteniamo - è il valore aggiunto reso possibile dal suo inserimento su Internet; si parla di Francoforte come luogo natale di Goethe, e noi colleghiamo la parola 'Francoforte' al sito Internet dell'ufficio di informazioni turistiche della città; si parla dello studio dell'ebraico da parte del giovane Goethe, e noi colleghiamo il passo a un corso di ebraico disponibile in rete; si parla dei suoi studi di anatomia, ed ecco un link al 'Visible Human Project', una impressionante raccolta di immagini e informazioni sull'anatomia umana. Alla fine, avremo reso un servizio al lettore? Non crediamo proprio: i collegamenti proposti sono dispersivi, la relazione con il contenuto del testo è minima, non vi è alcuna offerta di percorsi di ricerca strutturati e coerenti. Se tuttavia nell'articolo fosse presente un riferimento alle letture alchemiche di Goethe, e se per avventura su Internet fosse presente il testo di una delle opere lette e utilizzate dal poeta, il collegamento sarebbe probabilmente assai meno gratuito: laddove in un libro a stampa avremmo inserito una nota che rimandava a edizione e pagina del testo in questione, in un ipertesto in rete possiamo inserire un collegamento diretto. Il lettore interessato non avrà più bisogno (volendo) di interrompere la lettura per cercare di procurarsi - presumibilmente in una libreria specializzata - un'opera poco conosciuta e magari esaurita, ma potrà consultarla immediatamente (se siete scettici sulla possibilità di trovare in rete il testo dei trattati alchemici letti da Goethe, date un'occhiata alla URL http://www.levity.com/alchemy/texts.html). Esiste dunque una sorta di 'potere di link' da parte di chi realizza una pagina ipertestuale: perché l'ipertesto si riveli effettivamente uno strumento produttivo di strutturazione dell'informazione, e perché la ricchezza dei rimandi non si traduca in disordine, occorre che questo 'potere' non sia usato male. Ma come imparare a scegliere i collegamenti giusti? Si tratta di un campo in cui lo studio teorico è in gran parte da compiere: l'avvento degli ipertesti porta con sé problematiche finora poco esplorate, ed è probabile che la critica testuale avrà, nei prossimi decenni, un nuovo settore nel quale esercitarsi. Dal canto nostro, saremo soddisfatti se il lettore interessato a cimentarsi nella realizzazione di siti Web comprenderà l'importanza di scegliere in maniera oculata i legami ipertestuali forniti01. Naturalmente il problema riguarda non solo il fornitore ma anche il fruitore dell'informazione, che dovrà imparare a valutare e scegliere, fra i vari percorsi di navigazione che gli sono offerti, quelli più adeguati al suo scopo. Non meno importante è la capacità di associare all'informazione direttamente presente all'interno delle pagine Web anche della metainformazione che permetta di descrivere e strutturare in maniera adeguata il contenuto delle pagine stesse. Per capire l'importanza di questo compito, occorre soffermarsi brevemente sul concetto di metainformazione. Pensiamo a un qualunque oggetto informativo: un testo, un documento, una pagina web, una immagine, un file sonoro... Ebbene: ciascuno di questi oggetti contiene informazione, è fatto di informazione. Ma a questa informazione 'di primo livello', al contenuto del testo o del documento con il quale abbiamo a che fare, possiamo aggiungere dell'informazione ulteriore, informazione 'di secondo livello', che descrive e organizza l'informazione di primo livello. Così, ad esempio, possiamo pensare a un libro come all'informazione di primo livello, mentre la relativa scheda del catalogo di una biblioteca (che descrive il libro e ci dice dove trovarlo) ci offrirà metainformazioni relative al libro stesso (il nome dell'autore, il titolo, la casa editrice, la collocazione negli scaffali...). Questo esempio ci fa capire anche due altre caratteristiche importanti della metainformazione: in primo luogo, proprio come la scheda di una biblioteca, la metainformazione è assai spesso organizzata in una forma regolare e standardizzata, in modo da semplificarne l'uso come strumento per il reperimento e l'accesso all'informazione primaria. In secondo luogo, le metainformazioni non sono tutte uguali: alcune riguardano l'apparenza fisica del documento, altre la sua strutturazione logica, altre ancora la sua gestione... È facile capire che la distinzione fra informazione e metainformazione non è sempre chiarissima (talvolta una certa informazione può essere considerata 'di primo livello' da un certo punto di vista, e metainformazione da un altro...). Nondimeno la metainformazione - se pertinente e ben strutturata - è uno strumento prezioso. Pensate ad esempio alla ricerca di un file musicale: ciò che cercate, l'informazione primaria, è (la rappresentazione digitale di) una successione di suoni. Ma avreste ben scarse speranze di trovare la musica che cercate, in rete o altrove, senza sapere qual è il titolo del brano, chi lo ha scritto, chi lo ha eseguito. In questo caso la metainformazione descrittiva (testuale) è la migliore chiave di accesso per reperire un'informazione primaria che non è fatta di testo ma di suoni. Se avete provato a cercare brani musicali in rete, ad esempio attraverso un programma peer-to-peer per lo scambio di file (ne abbiamo parlato in una sezione precedente del libro), vi sarete certo accorti di come tale descrizione sia importante! Fra i molti scopi che ci spingono ad associare metainformazione a un determinato oggetto informativo, due sono particolarmente importanti: descrivere (possibilmente in base a criteri standardizzati) l'oggetto informativo in questione, in modo da aiutare a classificarlo, conservarlo e reperirlo, e organizzare o strutturare l'informazione primaria, talvolta esplicitando (anche in questo caso, nella maniera più standardizzata possibile) una struttura interna già presente, talvolta aggiungendone una ex novo. Così, ad esempio, possiamo organizzare in cartelle e sottocartelle la massa disordinata di documenti presenti nel nostro computer (e l'organizzazione che creiamo aggiunge metainformazione all'informazione primaria costituita dal contenuto dei file), o suddividere in paragrafi, capitoli, sezioni il libro che stiamo scrivendo. Talvolta la metainformazione (sia essa descrittiva, organizzativa o di altro genere) è aggiunta direttamente dall'autore dell'informazione primaria, talvolta è aggiunta da specialisti esterni (ad esempio archivisti e bibliotecari), talvolta è aggiunta dagli stessi utenti. Abbiamo sottolineato più volte come una delle caratteristiche più interessanti del Web sia la facilità con la quale chiunque può inserire nuova informazione al suo interno. Questo vantaggio, tuttavia, porta con sé un rischio non indifferente: purtroppo, infatti, chi inserisce informazione in rete si rende conto solo raramente dell'importanza di associare all'informazione primaria la metainformazione utile a descriverla, strutturarla e reperirla. Soprattutto, manca quasi sempre la consapevolezza di quanto sia importante - nell'aggiungere metainformazione - il farlo in maniera consapevole, rigorosa e uniforme, seguendo degli standard. Va tenuto presente, fra l'altro, che spesso l'aggiunta di metainformazione risponde a scopi decisamente poco rispettosi delle esigenze dell'utenza: far arrivare sul proprio sito il numero maggiore possibile di visitatori, non importa come. A molti di voi sarà così capitato, svolgendo una ricerca in rete, di arrivare a un sito pornografico o pubblicitario utilizzando chiavi di ricerca di tutt'altro genere: ebbene, i gestori di questi siti hanno, molto disinvoltamente, aggiunto alle loro pagine della metainformazione (sotto forma di parole chiave, o di testo nascosto) priva di qualunque legame col contenuto del sito, ma utile come 'esca' per attirare gli utenti: metainformazione fuorviante, dunque. Senza bisogno di arrivare a casi così eclatanti, è comunque la grande maggioranza delle informazioni inserite su Web che - a differenza di quanto accade di norma nel caso dell'informazione accessibile attraverso banche dati fortemente strutturate - risulta decisamente carente dal punto di vista della quantità e qualità della metainformazione. Ed è così proprio la risorsa di rete più varia e meno omogenea, e dunque quella che più avrebbe bisogno di organizzazione e descrizione, a risultare penalizzata nella sua fruibilità. Come vedremo in seguito, i linguaggi di marcatura (e in particolare quelli costruiti sulla base di XML) sono lo strumento più adatto per organizzare i contenuti del Web in maniera da rispondere a questa carenza di metainformazione. Quando si parla di 'web semantico' - un concetto (o un'utopia...) sul quale avremo occasione di tornare in seguito - si fa riferimento anche e soprattutto a questa esigenza. Ed è chiaro che, per raggiungere l'obiettivo di un Web più fruibile perché dotato di un'architettura informativa semanticamente più completa e coerente, occorre un forte lavoro di formazione e sensibilizzazione dell'utenza, assieme alla disponibilità di strumenti sofisticati ma di semplice uso per l'aggiunta e la gestione della metainformazione. Questa sensibilizzazione deve riguardare in primo luogo chi ha responsabilità dirette nell'inserimento di informazione in rete; ma non può non riguardare anche chi voglia acquisire la capacità di orientarsi all'interno del Web, svolgere ricerca, reperire informazione pertinente. Una buona conoscenza degli strumenti per la ricerca in rete passa dunque anche attraverso la comprensione della natura (e dei limiti) della metainformazione disponibile, e del modo nel quale i diversi strumenti di ricerca permettono di utilizzarla e valorizzarla. Dovremo tenere sempre presenti queste considerazioni, nell'accingerci a esaminare in dettaglio alcuni di questi strumenti. Note
|
 |
|||||||||
|
|
|
|||||||||
 |
 |
 |
|||||||||



| Inizio pagina |  |
 |