


 |
 |
||||||||||
 |
Temi e percorsi
Biblioteche in rete49Una delle metafore ricorrenti per descrivere il fenomeno Internet è quella della biblioteca. Come una biblioteca, la rete contiene una quantità enorme di documenti testuali (e non testuali); come una biblioteca ha i suoi cataloghi, i suoi strumenti di ricerca dell'informazione. Ma soprattutto, a differenza di ogni biblioteca reale del mondo, Internet sembra non avere limiti nella capacità di contenere e diffondere informazioni: sembra anzi realizzare, per mezzo della tecnologia, il mito della biblioteca universale, che accompagna l'umanità da molti secoli50. In realtà il parallelo metaforico tra la rete e il concetto di biblioteca universale è in parte fuorviante. Come abbiamo avuto modo di vedere parlando della ricerca di informazioni, lo spazio informativo della rete, e in particolare quello del Web, non è uno spazio completamente strutturato; al contrario, esso tende alla 'non organizzazione', in virtù della sua estrema dinamicità e fluidità. I vari strumenti di ricerca delle informazioni in rete dunque non rendono conto della totalità dei contenuti informativi presenti sulla rete stessa. Essi ne tracciano semmai mappe parziali e locali. Al contrario lo spazio informativo di una biblioteca è uno spazio completamente strutturato e organizzato, che trova una rappresentazione rigorosa nei vari tipi di cataloghi di cui essa è dotata. Potremmo dire che Internet assomiglia piuttosto alla fantastica Biblioteca di Babele immaginata da Jorge Luis Borges in uno dei suoi racconti più belli. La biblioteca borgesiana, che coincide con l'universo stesso (e in effetti l'universo della rete è l'informazione che contiene), pur ospitando tutti i libri che potrebbero essere scritti, non ha alcun criterio di organizzazione, e i suoi abitanti vagano in eterno alla ricerca del libro che ne spieghi la struttura, senza trovarlo mai. Nondimeno, sulla rete non mancano servizi informativi strutturati. Tra questi, sebbene sembri un gioco di parole, fanno bella mostra di sé proprio i servizi gestiti dalle biblioteche 'reali'. L'incontro tra Internet e biblioteche, che ha ormai una storia assai lunga, è stato favorito dal radicamento della rete nel mondo universitario statunitense. Gli Stati Uniti, infatti, hanno un enorme patrimonio di biblioteche51, tra cui spiccano le biblioteche universitarie, tradizionalmente dotate di servizi al pubblico assai avanzati ed efficienti. La predisposizione di servizi on-line da parte di queste istituzioni è stata, nella gran parte dei casi, un'evoluzione naturale. Ma, in generale, si deve rilevare che il fenomeno Internet ha suscitato nel mondo bibliotecario un vasto interesse anche al di fuori degli Stati Uniti. In virtù di tale interesse, Internet offre oggi una notevole quantità di servizi di tipo bibliotecario rivolti al pubblico generico, oltre ad alcuni servizi orientati maggiormente a una utenza professionale. Possiamo suddividere tale insieme di servizi nelle seguenti classi:
Il primo tipo di servizi è costituito dai siti Web approntati da singole biblioteche che offrono al pubblico informazioni, a vario livello di dettaglio, sulla biblioteca stessa, sulla sua collocazione, sui regolamenti e gli orari di accesso, sulla qualità e consistenza delle collezioni. I virtual reference desk offrono invece supporto agli utenti nella ricerca delle informazioni bibliografiche di loro interesse, e spesso consentono una interazione diretta (via mail, forum web o chat) con bibliotecari esperti di determinati settori. In alcuni casi è possibile trovare anche servizi avanzati come la prenotazione del prestito di un volume, o persino l'attivazione di procedure per il prestito interbibliotecario (di norma questi servizi sono approntati da biblioteche universitarie, e hanno un accesso limitato). Naturalmente la disponibilità di questi ultimi strumenti è legata alla presenza sul sito bibliotecario di un sistema di consultazione on-line del catalogo. Tali sistemi, detti OPAC (acronimo di On-line Public Access Catalog), sono senza dubbio una delle più preziose risorse informative attualmente disponibili sulla rete. Essi sono il prodotto di una lunga fase di innovazione tecnologica all'interno delle biblioteche, che ha avuto inizio sin dagli anni '60. L'automazione dei sistemi catalografici si è incontrata ben presto con lo sviluppo delle tecnologie telematiche, e in particolare con la diffusione della rete Internet nell'ambito del circuito accademico. Attualmente le biblioteche, grandi e piccole, universitarie, pubbliche e private, che, oltre ad avere un loro sito su Internet, danno agli utenti la possibilità di consultare on-line i cataloghi delle loro collezioni, sono nell'ordine delle decine di migliaia. Se la possibilità di effettuare ricerche bibliografiche in rete è ormai un dato acquisito, diverso è il discorso per quanto riguarda l'accesso diretto ai documenti. Infatti, il passaggio dalla biblioteca informatizzata alla biblioteca digitale è appena agli inizi. Con biblioteca digitale, in prima approssimazione, intendiamo un servizio on-line che produce, organizza e distribuisce sulla rete, in vario modo, versioni digitali di documenti e testi. A un livello intermedio si collocano i servizi di distribuzione selettiva dei documenti (document delivery). A questa categoria appartengono organizzazioni ed enti che archiviano e spogliano grandi quantità di pubblicazioni periodiche cartacee e che permettono a studiosi o ad altri enti bibliotecari di acquistare singoli articoli, che vengono poi spediti via posta, fax o e-mail, o resi accessibili sul Web. Una risorsa preziosa per chi deve effettuare attività di ricerca e non ha a disposizione una biblioteca dotata di una collezione di periodici sufficientemente esaustiva. Internet come fonte di informazione bibliograficaLa ricerca bibliografica è una delle attività fondamentali per tutti coloro che, per dovere (scolastico o professionale) o per piacere, svolgono una attività di studio e ricerca o in generale una forma di lavoro intellettuale. Essa ha la funzione di fornire un quadro ragionevolmente completo dei documenti pubblicati su un dato argomento, di descriverli in modo esauriente e di permetterne il reperimento effettivo. Al fine di effettuare una ricerca bibliografica si utilizzano soprattutto due tipi di strumenti: le bibliografie e i cataloghi bibliotecari. Entrambi questi strumenti si presentano in forma di un elenco di documenti identificati mediante alcune caratteristiche (o metadati) che ne permettono o facilitano l'individuazione: nome dell'autore, titolo, dati editoriali. La differenza tra bibliografia e catalogo consiste nel loro dominio di riferimento: una bibliografia contiene un elenco, esaustivo o meno, di documenti relativi a un determinato argomento o tema, o comunque collegati secondo un qualche criterio, senza far riferimento ai luoghi fisici in cui sono depositate delle copie di tali documenti; un catalogo, al contrario, contiene notizie relative a tutti e soli i documenti contenuti in una singola biblioteca (o in un gruppo di biblioteche), e fa esplicito riferimento alla collocazione fisica dell'esemplare (o degli esemplari) posseduto. Un elemento fondamentale sia delle bibliografie sia dei cataloghi è la chiave di accesso, cioè le caratteristiche del documento in base alle quali l'elenco viene ordinato e può essere consultato. Di norma le chiavi di accesso principali sono il nome (o i nomi) dell'autore, e il titolo. Tuttavia per i cataloghi bibliotecari molto utili sono anche le chiavi di accesso semantiche, quelle cioè che cercano di descrivere il contenuto del documento stesso. A tali chiavi possono corrispondere due tipi speciali di cataloghi: il catalogo alfabetico per soggetti, in cui i documenti sono ordinati in base a uno o più termini liberi che ne descrivono il contenuto, e il catalogo sistematico, in cui i documenti sono ordinati in base a uno schema di classificazione prefissato che articola il mondo della conoscenza in categorie e sottocategorie secondo una struttura ad albero che procede dall'universale al particolare52. Nel 'mondo reale' le bibliografie, di norma, sono contenute a loro volta in volumi o documenti pubblici, che possono essere acquistati o presi in prestito. I cataloghi invece sono ospitati, sotto forma di schedari, all'interno dei locali di una biblioteca, dove possono essere consultati al fine di stilare bibliografie o di accedere alle pratiche di consultazione e di prestito. Tradizionalmente, dunque, la ricerca bibliografica è una attività che richiede numerose fasi di consultazione di bibliografie e cataloghi, con annessi spostamenti, che talvolta possono imporre trasferte fuori città o persino all'estero. Lo sviluppo e la diffusione della rete sta modificando radicalmente il modo di effettuare la ricerca bibliografica. Internet, infatti, è diventata ormai la più preziosa ed esaustiva fonte di informazioni bibliografiche e oggi è possibile stilare una bibliografia completa, su qualsiasi argomento, stando comodamente seduti a casa davanti al proprio computer. Questo ha trasformato le modalità di lavoro della comunità scientifica, e più in generale di tutti coloro che per passione o professione debbano reperire notizie su libri e periodici. Anche su Internet le fonti di informazione bibliografica si articolano in bibliografie e cataloghi. Le prime, in genere, sono parte del contenuto informativo dei vari siti Web dedicati a una data disciplina o a un particolare argomento. Non esistono strumenti specifici di ricerca per quanto attiene a queste risorse, che vanno pertanto individuate mediante le strategie di reperimento delle informazioni in rete che abbiamo già visto nel capitolo 'Ricerca libera su Web'. Per quanto riguarda i cataloghi on-line, invece, è possibile fornire alcune nozioni più particolareggiate relative al loro reperimento su Internet, e alla loro consultazione53. Come abbiamo già detto, un catalogo bibliotecario consultabile attraverso i canali di comunicazione telematici viene comunemente definito On-line Public Access Catalog (OPAC). Un OPAC è costituito sostanzialmente da un database e da una interfaccia di accesso ai dati in esso archiviati. Un database dal punto di vista logico è composto da una serie di schede (record). Ogni record contiene la descrizione, organizzata per aree prefissate (o campi), di un determinato oggetto. Nel caso dei database catalografici, tali oggetti sono i documenti che fanno parte della collezione di una o più biblioteche. La struttura di un record catalografico è stata oggetto di un importante processo di standardizzazione internazionale. Infatti, l'introduzione dei sistemi informatici in ambito bibliotecario ha ben presto reso evidenti i vantaggi della collaborazione e dell'interscambio dei dati tra biblioteche. Di conseguenza, si è avvertita l'esigenza di sviluppare dei sistemi standard per la costruzione delle banche dati catalografiche, in modo da consentire lo scambio dei dati bibliografici e la costituzione di cataloghi elettronici collettivi. La comunità internazionale dei bibliotecari, riunita nella International Federation of Library Associations (IFLA, http://www.ifla.org/), a partire dalla metà degli anni '70 ha prodotto una serie di specifiche volte a conseguire tale fine. La più importante tra queste specifiche riguarda appunto il formato dei record catalografici, denominato UNIMARC (Universal Machine Readable Catalogue), che è ormai adottato (o quantomeno previsto come formato per l'input/output dei dati) in gran parte dei sistemi OPAC del mondo. A sua volta UNIMARC ricalca la struttura logica della scheda bibliografica standard definita nella International Standard Bibliographic Description (ISBD). ISBD prescrive infatti quali sono le informazioni che vanno fornite per caratterizzare un singolo documento:
Nel caso dei cataloghi digitali la scelta delle chiavi di accesso non va effettuata preliminarmente, come accade invece nei cataloghi a stampa al fine di ordinare il catalogo e di permetterne la consultazione. Un database infatti può essere ordinato in modo dinamico a seconda delle esigenze, e - soprattutto - la ricerca può avvenire in base a qualsiasi campo, o persino indipendentemente da un qualche campo (è possibile cioè indicare al sistema di cercare le occorrenze di una data stringa indipendentemente da dove appaia nel record). Ovviamente, le chiavi che possono effettivamente essere usate dagli utenti nelle ricerche dipendono dal tipo di interfaccia associata al database. Sfortunatamente, non esistono delle raccomandazioni unitarie sulle caratteristiche dell'interfaccia di interrogazione di un OPAC. In generale tutti gli OPAC permettono di effettuare ricerche usando come chiavi le principali intestazioni presenti in una normale scheda catalografica: autore, titolo, soggetto. Alcuni forniscono anche altre chiavi o filtri di ricerca, quali data o luogo di pubblicazione, editore, classificazione (nei vari sistemi CDD, CDU, LC, ecc.), codice ISBN. Parlando di interfacce degli OPAC, tuttavia, l'aspetto su cui mette conto soffermarci riguarda il tipo di strumento Internet su cui esse sono basate. I primi OPAC sono stati sviluppati e immessi in rete sin dall'inizio degli anni '80. A quell'epoca gli unici strumenti disponibili per l'accesso interattivo a un computer remoto erano i sistemi di emulazione terminale, il telnet o la sua versione specifica per mainframe IBM, denominata tn3270. Di conseguenza tutti gli OPAC che sono stati sviluppati in quegli anni hanno adottato delle interfacce utente basate su linea di comando o su schermate a carattere. Sebbene con il passare degli anni tali interfacce abbiano subito una certa evoluzione, è innegabile che questa modalità di accesso presentasse non poche difficoltà. Infatti essa richiedeva all'utente la conoscenza dei comandi e della sintassi di ricerca usata da ciascun OPAC; sintassi che, oltre a essere alquanto complessa, di norma variava da un OPAC all'altro. Con lo sviluppo del Web, un nuovo paradigma di accesso ha iniziato a farsi strada anche nelle interfacce degli OPAC, e ormai la consultazione tramite telnet è pressoché scomparsa. Al suo posto sono state sviluppate interfacce utente in ambiente Web, basate su moduli interattivi e dispositivi grafici (caselle combinate, menu a scelta multipla, caselle di testo e pulsanti, attivati con il sistema point and click) con cui un utente medio ha già dimestichezza e la cui curva di apprendimento all'uso è decisamente bassa. Dal lato server, questo ha significato lo sviluppo di appositi programmi di collegamento tra il database catalografico e il server Web, detti gateway. In questo campo un ruolo fondamentale è stato giocato dal protocollo Z39.5054, un protocollo sviluppato appositamente per far interagire un database e un modulo di ricerca senza che fosse necessario conoscere la particolare sintassi di ricerca del database. Se quest'ultimo è dotato di una interfaccia Z39.50, un client che implementi lo stesso protocollo può effettuare ricerche sul database anche in via remota. In una prima fase il protocollo Z39.50 è stato implementato direttamente in software client utilizzabili dall'utente. Ma ben presto tali software sono stati abbandonati per lasciare il posto a una architettura basata sul Web, in cui il server HTTP interagisce con un gateway Z39.50 che a sua volta può interrogare uno o più database contemporaneamente. L'utente finale in questo caso accede al servizio di ricerca direttamente mediante un pagina Web, usando un comune browser. I repertori di siti bibliotecariI siti di carattere bibliotecario accessibili attraverso Internet sono ormai molte migliaia, ed è ovviamente impossibile elencarli tutti. Come sempre, però, la rete fornisce ai suoi utenti degli strumenti di orientamento di secondo livello. Esistono infatti diversi 'repertori' di siti bibliotecari, che possono essere consultati per scoprire l'indirizzo di rete della biblioteca che si sta cercando (posto che ne abbia uno), o per individuare quali biblioteche in una certa area geografica siano dotate di servizi in rete (occorre tuttavia ricordare che non tutte le biblioteche dotate di un sito Web hanno anche un OPAC pubblico). Rientrano in questa categoria tutti i repertori di siti bibliotecari che fanno parte di più vasti repertori di risorse di rete, come quello organizzato da Yahoo! (http://www.yahoo.com/ Reference/ Libraries/) o da Google (http://directory.google.com/ Top/ Reference/ Libraries/). Passando ai repertori specializzati in siti bibliotecari, uno dei più aggiornati e completi è Libweb realizzato alla University of Berkeley, in California, a cura di Thomas Dowling (l'indirizzo è http://sunsite.berkeley.edu/ Libweb/). L'elenco è diviso per aree geografiche (Stati Uniti, Africa, Asia, Australia, Europa, Sud America, Canada), e successivamente per nazioni. Solo il ramo dedicato alle biblioteche statunitensi è articolato anche per tipo di biblioteca. Oltre alla possibilità di scorrere il repertorio, Libweb fornisce anche un sistema di ricerca per parole chiave, basato su una sintassi abbastanza semplice. Molto completo è anche il repertorio Bibliotheks-OPACs und Informationsseiten (http://www.hbz-nrw.de/ produkte_dienstl/ toolbox/) cu- rato da Hans-Dieter Hartges, ospitato sul sito del Hochschulbibliothekszentrum (HBZ), una organizzazione che realizza un catalogo unico per numerose biblioteche accademiche tedesche, dove si possono trovare moltissime informazioni sulle risorse bibliotecarie in Germania. Un altro ottimo repertorio globale di OPAC è Libdex (http://www.libdex.com/). Nato da un progetto di Peter Scott, si è evoluto in un vero e proprio portale verticale dedicato al mondo delle biblioteche. La directory può essere scorsa in base a due criteri di ordinamento: per aree geografiche e nazioni e per tipo di software. Quest'ultima categoria articola i vari OPAC in base al prodotto di catalogazione utilizzato, e può essere utile per coloro che hanno dimestichezza con l'interfaccia e la sintassi di ricerca di uno di essi. Sono molte anche le biblioteche italiane che hanno realizzato dei sistemi OPAC su Internet. Il migliore repertorio di OPAC italiani è ospitato sull'ottimo sito Web della Associazione Italiana Biblioteche (AIB, http://www.aib.it/), coordinato da Riccardo Ridi. Il repertorio (il cui indirizzo è http://www.aib.it/aib/lis/opac1.htm) è suddiviso in due sezioni: una dedicata ai cataloghi collettivi nazionali, e una dedicata ai cataloghi collettivi regionali, provinciali, comunali e ai cataloghi di singole biblioteche. Per ciascun OPAC vengono fornite delle brevi note informative e una serie di link alle pagine di ricerca e alle eventuali pagine di istruzioni per l'uso. Oltre al repertorio, l'AIB, in collaborazione con il CILEA, ha realizzato il Meta-OPAC Azalai Italiano (MAI). Si tratta di un sistema di interrogazione unificato di un'ampia raccolta di cataloghi bibliotecari italiani su Internet, che permette di inviare una medesima ricerca a più OPAC contemporaneamente. MAI permette di selezionare in anticipo quali cataloghi interrogare (in base alla collocazione geografica o al tipo di biblioteca), e poi fornisce una maschera in cui è possibile specificare i termini di ricerca (ovviamente occorre tenere conto che non tutte le chiavi di ricerca sono disponibili su tutti i sistemi). Il risultato dell'interrogazione viene composto in una unica pagina Web che mostra l'output di ciascun catalogo, completo di pulsanti e collegamenti per visualizzare la scheda bibliografica o per raffinare la ricerca. Un altro repertorio di siti bibliotecari italiani (anche se non necessariamente di cataloghi on-line) è Biblioteche italiane (http://www.biblio.polito.it/ it/ documentazione/ biblpoli.html), a cura del Sistema bibliotecario del Politecnico di Torino, anch'esso organizzato per aree geografiche. Il Servizio Bibliotecario Nazionale e altri OPAC italianiIl numero di OPAC italiani censito dall'esaustivo repertorio dell'AIB ha ormai superato la soglia delle quattrocento unità. Vi si trovano grandi cataloghi collettivi e piccoli OPAC di biblioteche locali. Per avere un quadro generale rimandiamo dunque a tale risorsa. In questa sede ci soffermeremo invece su alcuni OPAC italiani di particolare rilievo. Tra tutti, il più importante in assoluto è senza dubbio il Servizio Bibliotecario Nazionale (SBN), che produce il catalogo collettivo delle biblioteche italiane. SBN, che ha avuto una storia alquanto travagliata, dal 1992 è entrato finalmente in funzione e fornisce oggi un servizio di buon livello. Vi aderiscono finora 1.608 istituti bibliotecari, tra biblioteche statali (incluse le Biblioteche Nazionali Centrali di Roma e Firenze), universitarie, comunali e di istituzioni pubbliche, organizzate in 49 poli locali. Ciascun polo gestisce un catalogo collettivo locale, che poi confluisce nell'indice SBN, il catalogo unico nazionale gestito dall'Istituto Centrale per il Catalogo Unico (ICCU). Il servizio SBN è suddiviso in più banche dati catalografiche, divise per tipologia di documenti, che vengono incrementate continuamente. Ricordiamo in particolare:
Sono inoltre disponibili altri cataloghi specializzati, come quello della 'letteratura grigia', quello della Discoteca di Stato, e l'elenco di tutte le biblioteche italiane. Ulteriori informazioni relative al sistema SBN sono disponibili sul sito Web dell'ICCU, all'indirizzo http://www.iccu.sbn.it/. L'accesso all'OPAC SBN è possibile mediante due interfacce Web, basate entrambe su un gateway Z39.50. La prima, presente in rete da diversi anni, si chiama Opac SBN (http://opac.sbn.it/), e insiste solo sugli indici SBN. La maschera di interrogazione è assai articolata, e permette di effettuare due tipi di ricerche. La ricerca base, che si applica a tutte le basi dati, fornisce una maschera di interrogazione contenente le chiavi 'autore', 'titolo', 'soggetto' e 'classificazione'; tutte le parole fornite nei campi sono considerate come termini di ricerca obbligatori. Le ricerche specializzate invece si applicano a una sola delle banche dati. Oltre a fornire le ulteriori chiavi di ricerca 'data di pubblicazione', 'collezione', 'parole chiave' e 'ISBN/ISSN', esse permettono di specificare degli operatori booleani che si applicano ai termini specificati nei singoli campi, al fine di effettuare interrogazioni molto raffinate. In entrambi i casi è possibile indicare l'ordinamento e il formato dell'output. Il risultato di una ricerca, oltre alle schede bibliografiche dettagliate relative ai documenti rintracciati, fornisce anche l'elenco delle biblioteche che li possiedono, con relativa collocazione. La seconda interfaccia, uscita dalla fase sperimentale di recente, si chiama SBN On-line (http://sbnonline.sbn.it/) e permette di consultare oltre agli indici SBN anche altri archivi catalografici e bibliografici. L'interfaccia è più ricca di chiavi di ricerca e si basa su un sistema di menu a tendina. Sono disponibili due modalità di ricerca (semplice e avanzata, che permette di combinare più chiavi di ricerca con operatori booleani) e la scansione degli indici dei nomi, dei titoli e dei soggetti. Oltre al catalogo unico nazionale, esistono in rete alcuni OPAC realizzati dai poli regionali di SBN (in questo caso non si può accedere all'intero catalogo unico, ma solo alle sezioni realizzate direttamente dal polo in questione). Ad esempio, ricordiamo il polo universitario bolognese, il cui indirizzo Web è http://www.cib.unibo.it/, che ha sviluppato una maschera di interrogazione molto efficace e di semplice utilizzo; il polo romano che consente di interrogare i suoi cataloghi usando due diversi sistemi OPAC (http://sbn.cics.uniroma1.it/ CatalogoLoc/ catalogo.htm); il polo regionale del Piemonte, con il servizio 'Librinlinea' (http://www.regione.piemonte.it/opac/). Un'altra importante risorsa bibliografica italiana è il Catalogo Italiano dei Periodici (ACNP), nato per iniziativa dell'Istituto di Studi sulla Ricerca e Documentazione Scientifica (ISRDS-CNR) nel 1970. Il catalogo contiene le descrizioni bibliografiche, e in parte gli spogli, dei periodici e delle riviste possedute da oltre duemila biblioteche sparse sul territorio nazionale. Al momento, la consistenza della banca dati ammonta a quasi centomila periodici.
La consultazione avviene mediante una interfaccia Web messa a punto dal CIB di Bologna e raggiungibile all'indirizzo http://www.cib.unibo.it/acnp/. La maschera di ricerca, piuttosto semplice, permette di interrogare il catalogo per titolo del periodico, ente responsabile, numero ISSN, codice di classificazione CDU, e codice della biblioteca. La ricerca fornisce in prima istanza una pagina con l'elenco dei periodici che rispondono ai criteri specificati, dalla quale è poi possibile passare a una pagina che indica tutte le biblioteche in possesso del periodico cercato (con relative informazioni). Se disponibili, si possono consultare anche gli spogli degli articoli (con l'eccezione della parte di database degli articoli realizzata dall'ISI, consultabile solo dall'interno dell'Università di Bologna).
OPAC e siti bibliotecari nel resto del mondoCome detto, gli OPAC disponibili su Internet sono diverse migliaia, ed è impossibile rendere conto di queste risorse in modo sistematico. Ci limiteremo pertanto a esaminare alcuni di essi, in genere realizzati dalle grandi biblioteche nazionali. La nostra rassegna non può che iniziare dalla più grande e importante biblioteca del mondo, la Library of Congress. Si tratta della biblioteca nazionale degli Stati Uniti, fondata nel 1800 con lo scopo di acquisire tutti i libri e i documenti necessari ai rappresentanti del Congresso, e divenuta poi sede del deposito legale delle pubblicazioni edite negli Stati Uniti. Ma la collezione della biblioteca, nel corso di questi duecento anni, è cresciuta ben al di là della sua missione statutaria. Nei suoi edifici di Washington sono conservati oltre cento milioni di documenti e pubblicazioni in 450 lingue (tra cui oltre nove milioni di libri), oltre a una sterminata mediateca; per alcune lingue le collezioni sono persino più complete di quelle delle biblioteche nazionali di riferimento. Oggi la Library of Congress non è solo una biblioteca, ma un vero e proprio centro di produzione culturale e di ricerca scientifica, anche e soprattutto nel campo delle nuove tecnologie: la catalogazione digitale, lo sviluppo di protocolli e standard per i metadati come MARC 21 (variante americana di MARC), Z39.50, METS (Metadata Encoding and Transmission Standard, un linguaggio XML per le creazione di metadati per risorse elettroniche), EAD (Encoded Archival Description, un linguaggio XML per la descrizione di materiale archivistico), la digitalizzazione del patrimonio culturale, sono solo alcuni dei temi intorno ai quali sono creati centri di ricerca e avviati progetti sperimentali. Il sito Web della LC, dunque, è una vera e propria miniera di informazioni e documentazione sia per gli addetti ai lavori, sia per l'utenza generale. Ma ovviamente il vero cuore dei servizi on-line realizzati da questa grande istituzione è rappresentato dal suo OPAC, costituito da una serie di archivi, ciascuno contenente notizie relative a una particolare tipologia di documenti. Per consultarlo sono disponibili due interfacce in modalità Web, basate su un gateway Z39.50 e ampiamente documentate in esaurienti pagine di aiuto (l'indirizzo diretto è http://catalog.loc.gov/). La prima, Basic search, consente di effettuare ricerche mediante un insieme limitato di chiavi (tra cui titolo, autore, soggetto e parole chiave). La seconda, Guided Search, consente di effettuare la ricerca su un insieme più vasto di chiavi, elencate in un menu a tendina. È possibile combinare due chiavi di ricerca mediante operatori booleani e inserire elenchi di termini da ricercare, che possono essere considerati come termini distinti (presi tutti insieme o in alternativa) o come un unico sintagma. In entrambi i casi, si possono specificare delle limitazioni sulla ricerca in base alla tipologia, al luogo e alla data di pubblicazione dei documenti cercati. L'output della ricerca, che include in molti casi un abstract, può essere visualizzato come scheda breve, come scheda completa e come record in formato MARC. Il sito Web della Library of Congress, come si è accennato, fornisce oltre al catalogo anche un'ingente mole di informazioni e documenti. In particolare segnaliamo il progetto Thomas, che dà accesso ai testi delle leggi in esame alla Camera e al Senato degli Stati Uniti e agli atti delle discussioni parlamentari. Altrettanto interessante è il progetto American Memory, una biblioteca digitale che contiene documenti, testi a stampa e manoscritti digitalizzati, registrazioni sonore, fotografie e filmati relativi alla storia americana, dotato di un suo sistema di ricerca. Sempre per quanto riguarda gli Stati Uniti, va detto che le biblioteche di tutte le più importanti università sono collegate a Internet, e offrono servizi OPAC, di norma raggiungibili mediante espliciti link segnalati sulle home page delle rispettive sedi universitarie. La maggior parte di questi OPAC raccoglie in un catalogo collettivo tutti i singoli cataloghi dei molti istituti bibliotecari presenti in ciascun campus, ed è dotata di accesso Web. A puro titolo esemplificativo ricordiamo qui la biblioteca della prestigiosa Harvard University, la più grande biblioteca universitaria del mondo (possiede circa 12 milioni di volumi) e la più antica degli Stati Uniti (fu fondata infatti nel 1638), il cui OPAC, battezzato HOLLIS, è raggiungibile dal sito http://lib.harvard.edu/. Le biblioteche del Massachusetts Institute of Technology, il cui OPAC collettivo Barton è raggiungibile dal sito http://libraries.mit.edu/. La biblioteca della Dartmouth University, raggiungibile all'indirizzo http://www.dartmouth.edu/library/. Le biblioteche della Yale University, il cui OPAC ORBIS è su Web all'indirizzo http://orbis.library.yale.edu/. In alcuni casi sono stati realizzati anche dei cataloghi interbibliotecari unificati. Tra questi molto importante sia per la consistenza degli archivi sia per le istituzioni che raccoglie è Melvyl. Si tratta di un progetto che riunisce in un catalogo collettivo gli archivi catalografici della California State Library e di tutte le biblioteche universitarie della California (tra cui UCLA, Berkeley e Stanford), oltre a una serie di banche dati bibliografiche. L'OPAC di Melvyl è accessibile all'indirizzo http://www.dla.ucop.edu/.
Passando alle risorse bibliotecarie europee, ricordiamo innanzitutto la prestigiosa British Library (http://www.bl.uk/). Il fondo della BL è veramente enorme, e ammonta a oltre 150 milioni di documenti in tutte le lingue. A fronte di tanto materiale, raccolto nel corso di 250 anni di storia, non esiste un catalogo unico. Ogni collezione infatti ha un suo catalogo, spesso di formato e struttura particolare. Per questa ragione la BL ha potuto realizzare dei servizi on-line solo in anni molto recenti. Il catalogo pubblico British Library Public Catalogue, accessibile sul Web (http://blpc.bl.uk/), contiene notizie relative a circa 10 milioni di titoli.
Un'altra grande risorsa bibliotecaria anglosassone è il catalogo unico delle biblioteche dell'Università di Oxford. Il sistema informativo bibliotecario di Oxford, denominato OLIS (Oxford University Libraries System), raccoglie i cataloghi informatizzati di oltre cento tra biblioteche generali, di college e di facoltà. Tra le varie biblioteche di questa prestigiosa università ricordiamo la Bodleian Library, una delle maggiori biblioteche del mondo per le scienze umane, il cui catalogo elettronico è, però, limitato alle accessioni posteriori al 1988. La consultazione degli OPAC può essere effettuata sia tramite telnet (l'indirizzo diretto è telnet://library.ox.ac.uk) sia tramite GeoWeb, un gateway Z39.50 recentemente allestito, il cui indirizzo è http://library.ox.ac.uk/. Anche la monumentale Bibliothèque Nationale di Parigi fornisce accesso al suo catalogo tramite Internet. L'OPAC della BNF, battezzato OPALE, uno dei più 'antichi' della rete, fino alla metà del 1999 era accessibile esclusivamente tramite una sessione telnet. Dal maggio del '99 è stata finalmente attivata l'interfaccia Web, battezzata OPALE-PLUS, che consente di interrogare un archivio contenente circa 7 milioni di notizie bibliografiche relative ai documenti conservati nella biblioteca. L'accesso a OPALE-PLUS è collocato nel sito Web della biblioteca, il cui indirizzo è http://www.bnf.fr/. Oltre al catalogo, il sito offre una serie di informazioni e di servizi, tra cui l'accesso a OPALINE, il catalogo delle collezioni speciali, e la banca dati multimediale Gallica, su cui torneremo nel paragrafo dedicato alle biblioteche digitali. La Biblioteca Vaticana, con le sue preziose raccolte di manoscritti e incunaboli, non era ancora presente con il proprio OPAC in rete nel momento in cui scrivevamo la precedente edizione di questo manuale, ma è nel frattempo arrivata anch'essa su Web; l'indirizzo è http://www.vaticanlibrary.vatlib.it/. Chiudiamo con un una risorsa bibliotecaria di area tedesca, il già ricordato Karlsruher Virtueller Katalog (http://www.ubka.uni-karlsruhe.de/kvk.html), un meta-OPAC basato sul protocollo Z39.50 che consente di consultare i cataloghi di alcune fra le maggiori biblioteche tedesche e anglosassoni. Cataloghi editoriali e librerie in reteAccanto agli OPAC delle biblioteche, su Internet si trovano anche altri due tipi di archivi che contengono informazioni bibliografiche: i cataloghi on-line delle case editrici e quelli delle librerie. I cataloghi editoriali sono uno strumento essenziale per il bibliotecario, ma possono essere molto utili anche per uno studioso, o per un normale lettore. Essi infatti consentono di essere costantemente aggiornati sui vari titoli pubblicati. I tradizionali cataloghi editoriali su carta vengono rilasciati con frequenza prefissata, e molto spesso contengono informazioni molto succinte sui titoli disponibili, anche a causa degli elevati costi di stampa. I cataloghi editoriali su World Wide Web possono invece essere aggiornati in tempo reale, e sono in grado di offrire una informazione più completa su ciascun titolo: si va dall'immagine della copertina a riassunti o estratti di interi capitoli di un libro. Queste informazioni mettono in grado il lettore di farsi un'idea migliore della qualità o della rilevanza di un testo. Recentemente, alcune case editrici hanno affiancato ai servizi informativi anche dei servizi di vendita diretta on-line. Le case editrici che dispongono di versioni elettroniche dei loro cataloghi sono moltissime. Un elenco molto esteso degli editori che dispongono di un sito Web è consultabile attraverso Yahoo!, all'indirizzo http://dir.yahoo.com/ Business_and_Economy/ Shopping_and_Services/ Publishers/ Segnaliamo per qualità ed efficienza il catalogo della grande casa editrice statunitense Prentice Hall (http://www.prenhall.com/). Le notizie bibliografiche e editoriali sono molto complete. Inoltre dalla pagina relativa a un titolo si può direttamente ordinare il volume, mediante il servizio di vendita della più grande libreria telematica del mondo, Amazon, della quale abbiamo già avuto occasione di parlare e su cui torneremo tra breve. Molto ben fatto anche il catalogo editoriale della O'Reilly Associates (http://www.ora.com/), specializzata nel settore informatico; o quello della MIT Press (http://www-mitpress.mit.edu/), casa editrice universitaria legata al prestigioso ateneo di Boston. Per quanto riguarda l'Italia, ormai la maggior parte delle case editrici possiede dei siti Web, dotati di sistemi di interrogazione del catalogo. Un utile punto di partenza per avere informazioni sul mercato librario nazionale è il sito Alice.it (http://www.alice.it/) realizzato da Informazioni Editoriali55. Accanto a moltissime informazioni sui nuovi titoli in uscita, interviste e curiosità, vi si trova un elenco delle editrici on-line molto completo (http://www.alice.it/ publish/ net.pub/ pnethome.htm). Tra le altre, ricordiamo la casa editrice Laterza (http://www.laterza.it/), che pubblica il libro che state leggendo. Per merito anche della prima edizione di questo manuale, apparsa nel 1996, la Laterza è stata fra le prime case editrici in Italia a sperimentare l'integrazione tra testo elettronico su Web ed edizione a stampa. Per quanto riguarda le librerie in rete, il riferimento obbligato è senza dubbio quello ad Amazon.com (http://www.amazon.com/), la più grande libreria su Web e - come abbiamo già ricordato - uno dei primi e più avanzati siti di commercio elettronico. Amazon è disponibile anche in versioni nazionalizzate rivolte ai mercati inglese, francese, tedesco e spagnolo, mentre il varo della versione italiana del sito, della quale pure si parla da tempo, sembra essere stato ritardato (speriamo non indefinitamente) dalle esigenze di tagli agli investimenti prodotte dalla crisi della new economy. Va detto comunque che Amazon è una delle società che sembrano aver superato meglio questa crisi, tanto che le sue strategie di organizzazione aziendale costituiscono veri e propri 'casi di studio' al riguardo. Nonostante i notevoli investimenti effettuati, e nonostante il sito comunque di ottimo livello, la catena statunitense Barnes & Noble (http://www.barnesandnoble.com/) non è riuscita a scalzare Amazon dalla posizione di assoluto predominio nel settore. In Italia, le due librerie in rete con maggiore disponibilità di catalogo sono al momento la 'veterana' Internet Bookshop (http://www.ibs.it/) e BOL (http://www.bol.com/). Gli indirizzi Web di numerose altre librerie in rete sono comunque reperibili nell'omonima sezione del già ricordato sito di Alice.it. Un nuovo paradigma: la biblioteca digitaleL'informatizzazione e la messa in rete dei cataloghi, pur avendo radicalmente trasformato le modalità di organizzazione e di ricerca dei documenti su supporto cartaceo, non ha modificato i procedimenti di accesso al contenuto dei documenti stessi, né la natura fondamentale della biblioteca in quanto luogo fisico di conservazione e distribuzione dei documenti testuali. A far emergere un paradigma affatto nuovo in questo ambito sono intervenuti gli sviluppi delle tecnologie dell'informazione e della comunicazione negli ultimi quindici anni. In particolare, due sono i fattori che hanno fornito la maggiore spinta propulsiva in questa direzione. In primo luogo, la diffusione e la autonomizzazione dei documenti digitali. Lo sviluppo tecnologico nel settore dei nuovi media ha infatti conferito ai supporti digitali lo status di possibili o probabili sostituti dei supporti tradizionali, sia nell'ambito della comunicazione linguistica (libro, nelle sue varie forme, rivista, giornale, rapporto, relazione, atto, certificato, ecc.), sia in quello della comunicazione visiva (fotografia, pellicola, ecc.) e sonora (cassetta, vinile). Il documento digitale, dunque, ha assunto una funzione autonoma rispetto alla sua (eventuale) fissazione su un supporto materiale. In secondo luogo, lo sviluppo e la diffusione delle tecnologie telematiche in generale, e della rete Internet in particolare. Questa diffusione sta trasformando radicalmente le modalità di distribuzione e di accesso alle informazioni, e sta determinando la progressiva digitalizzazione e telematizzazione della comunicazione scientifica che, specialmente in alcuni contesti disciplinari, si svolge ormai quasi completamente mediante pubblicazioni on-line su Internet. La convergenza tra diffusione del documento elettronico e sviluppo delle tecnologie di comunicazione telematica ha favorito la sperimentazione di nuove forme di archiviazione e diffusione del patrimonio testuale. In questo contesto si colloca l'emergenza del paradigma della biblioteca digitale. Le prime pionieristiche sperimentazioni nel campo delle biblioteche digitali sono quasi coeve alla nascita di Internet. Ma è soprattutto dall'inizio degli anni '90 che si è assistito a una notevole crescita delle iniziative e dei progetti, alcuni dei quali finanziati da grandi enti pubblici in vari paesi. Parallelamente, si è avuta una crescente attenzione teorica e metodologica dedicata al tema delle biblioteche digitali, tanto da giustificare la sedimentazione di un dominio disciplinare autonomo. I primi spunti in questo campo precedono la nascita di Internet e persino lo sviluppo dei computer digitali. Ci riferiamo al classico articolo di Vannevar Bush How we may think, nel quale l'autore immagina l'ormai celeberrimo Memex: una sorta di scrivania automatizzata, dotata di un sistema di proiezione di microfilm e di una serie di apparati in grado di collegare tra loro i documenti su di essi riprodotti. Lo stesso Bush, introducendo la descrizione del suo ingegnoso sistema di ricerca e consultazione di documenti interrelati, lo definì una «sorta di archivio e biblioteca privati»56. Un'approssimazione maggiore all'idea di biblioteca digitale (sebbene il termine non compaia esplicitamente) si ritrova nel concetto di docuverso elaborato da Ted Nelson, cui dobbiamo anche la prima formulazione esplicita dell'idea di ipertesto digitale57. Nelson, sin dai suoi primi scritti degli anni '60, descrive un sistema ipertestuale distribuito (che poi battezzerà Xanadu) costituito da una rete di documenti elettronici e dotato di un complesso sistema di indirizzamento e di reperimento delle risorse. La convergenza teorica e tecnica tra biblioteche digitali e sistemi ipertestuali distribuiti trova pieno compimento con la nascita e lo sviluppo del World Wide Web. Tuttavia, questa convergenza non ci consente di distinguere con sufficiente chiarezza tra l'idea generica di un sistema di pubblicazione on-line di documenti digitali, l'idea di ipertesto distribuito e una nozione più formale e rigorosa di biblioteca digitale58. Se tale nozione individua un'area specifica di applicazione, occorre precisare in che modo la 'biblioteca digitale' si differenzi da quella tradizionale, in che modo ne erediti funzioni e caratteristiche e come, infine, sia possibile distinguerla da altre tipologie di sistemi informativi (come appunto il Web in generale). Naturalmente non possiamo in questa sede soffermarci su tali aspetti teorici. Ci limitiamo a osservare che il contenuto di una biblioteca digitale è costituito da un sistema di documenti, dotato di un'organizzazione complessiva dovuta a un agente intenzionale distinto dai creatori dei singoli documenti, e da un sistema di metainformazioni (o metadati) a essi correlati. I metadati sono funzionali alla codifica, al reperimento, alla preservazione, alla gestione e alla disseminazione di documenti o di loro specifiche sezioni. Un completo servizio di biblioteca digitale (composto da risorse hardware, sistemi di rete, software di stoccaggio dei dati, interfacce utente e sistemi di information retrieval) dovrebbe consentire l'implementazione di tali funzioni. In questo senso possiamo distinguere una biblioteca digitale da un insieme non organizzato di informazioni assolutamente eterogenee come World Wide Web, ma anche da molti archivi testuali che attualmente sono disponibili su Internet e che si presentano come 'depositi testuali' piuttosto che come vere e proprie biblioteche. Le varie tipologie di biblioteche digitali su InternetInternet ormai ospita un ingente numero di banche dati testuali, di varia tipologia. Gran parte di queste esperienze sono ancora lontane dall'incarnare esattamente la definizione di biblioteca digitale che abbiamo proposto nel paragrafo precedente. Ma allo stesso tempo esse dimostrano l'enorme potenzialità della rete come strumento di diffusione dell'informazione e come laboratorio di un nuovo spazio comunicativo, lasciando prefigurare una nuova forma nella diffusione e fruizione del sapere. D'altra parte qualsiasi definizione teorica rappresenta una sorta di ipostatizzazione ideale e astratta di fenomeni reali che presentano sempre idiosincrasie e caratteri particolari. E questo è tanto più vero in un mondo proteico e in continua evoluzione come quello della rete Internet. Nell'ambito di questa vasta e variegata congerie di progetti e sperimentazioni è tuttavia possibile individuare alcuni tratti distintivi che ci consentono di tracciare una provvisoria tassonomia. Il primo criterio in base al quale possono essere suddivise le attuali biblioteche digitali su Internet è relativo ai formati con cui i documenti vengono archiviati alla fonte e distribuiti agli utenti (formati, si noti, non necessariamente coincidenti). Se si analizza lo spettro dei formati di codifica correntemente adottati nelle sperimentazioni di biblioteche digitali, si riscontrano le seguenti tipologie:
Un secondo aspetto in base al quale possono essere suddivise le biblioteche digitali in rete riguarda le modalità di accesso e di consultazione dei documenti elettronici in esse contenuti. In generale possiamo distinguere tre modalità con cui un utente può accedere ai documenti archiviati in una biblioteca digitale:
Naturalmente ognuna di queste modalità non esclude le altre. Tuttavia sono molto poche le biblioteche digitali attualmente esistenti che offrano tutti e tre i servizi. In genere sono molto diffusi i primi due tipi di accesso, mentre i servizi di ricerca e analisi dei documenti sono disponibili solo in alcuni sistemi sviluppati in ambito bibliotecario o accademico. Un ultimo criterio di classificazione delle biblioteche digitali su Internet, infine, riguarda il tipo di ente, organizzazione o struttura che ha realizzato la biblioteca, e ne cura la manutenzione. Da questo punto di vista possiamo ripartire i progetti attualmente in corso in tre classi:
Il primo gruppo è costituito da una serie di sperimentazioni avviate dalle grandi biblioteche nazionali o da consorzi bibliotecari, con forti finanziamenti pubblici o, per quanto attiene al nostro continente, comunitari. Il secondo gruppo è costituito da sperimentazioni e servizi realizzati in ambito accademico. Si tratta in genere di progetti di ricerca specializzati, che possono disporre di strumenti tecnologici e di competenze specifiche molto qualificate, a garanzia della qualità scientifica delle edizioni digitalizzate. Tuttavia non sempre i materiali archiviati sono liberamente disponibili all'utenza esterna. Infatti vi si trovano assai spesso materiali coperti da diritti d'autore. Accanto alle biblioteche digitali realizzate da soggetti istituzionali, si collocano una serie di progetti, sviluppati e curati da organizzazioni e associazioni private di natura volontaria. Queste banche dati contengono testi che l'utente può prelevare liberamente e poi utilizzare sulla propria stazione di lavoro; di norma, tutti i testi sono liberi da diritti d'autore. Le edizioni elettroniche contenute in questi archivi non hanno sempre un grado di affidabilità filologica elevato. Tuttavia si tratta di iniziative che, basandosi sullo sforzo volontario di moltissime persone, possono avere buoni ritmi di crescita, e che già oggi mettono a disposizione di un vasto numero di utenti una notevole mole di materiale altrimenti inaccessibile. I repertori di biblioteche digitali e archivi testualiIl numero di biblioteche digitali presenti su Internet è oggi assai consistente, e nuove iniziative vedono la luce ogni mese. Nella maggior parte dei casi questi archivi contengono testi letterari o saggistici in lingua inglese, ma non mancano archivi di testi in molte altre lingue occidentali, archivi di testi latini e greci, e biblioteche speciali con fondi dedicati a particolari autori o temi. Nei prossimi paragrafi ci occuperemo di alcune iniziative che ci sembrano a vario titolo esemplari. Per un quadro generale ed esaustivo, invece, invitiamo il lettore a consultare i vari repertori di documenti elettronici e biblioteche digitali disponibili in rete. Esistono due tipi di meta-risorse dedicate ai testi elettronici: repertori di progetti nel campo delle biblioteche digitali e meta-cataloghi di testi elettronici disponibili su Internet. Tra i primi ricordiamo il Digital Initiative Database (http://www.arl.org/did/) realizzato dalla Association of Research Libraries (ARL). Si tratta di un database che contiene notizie relative a iniziative di digitalizzazione di materiali documentali di varia natura in corso presso biblioteche o istituzioni accademiche e di ricerca statunitensi. Le ricerche possono essere effettuate per nome del progetto o per istituzione responsabile dello stesso, ma si può anche scorrere il contenuto dell'intero database. Per i progetti di biblioteche digitali sviluppati in ambito accademico, molto utile è la Directory of Electronic Text Centers compilata da Mary Mallery (http://harvest.rutgers.edu/ ceth/ etext_directory/) del Center for Electronic Texts in the Humanities (CETH). Si tratta di un inventario ragionato di archivi testuali suddiviso per enti di appartenenza. Per ognuno dei centri elencati, oltre a un link diretto, vengono forniti gli estremi dei responsabili scientifici, l'indirizzo dell'ente, e una breve descrizione delle risorse contenute. Anche la Text Encoding Initiative, sul suo sito Web, ha realizzato un elenco dei vari progetti di ricerca e archivi testuali basati sulle sue fondamentali norme di codifica. La pagina 'Projects using the TEI' (il cui indirizzo Web esatto è http://www.tei-c.org/ Applications/) fornisce informazioni e link diretti alle home page di più di cinquanta iniziative, tra le quali si annoverano alcune tra le più interessanti e avanzate esperienze di biblioteche digitali attualmente in corso. Un'altra importante fonte di informazione circa le applicazioni delle tecnologie SGML in ambito scientifico è costituita dalla sezione 'Academic Projects and Applications' delle XML Cover Pages curate da Robin Cover (http://xml.coverpages.org/ acadapps.html). Molto ricco di informazioni relative al tema delle biblioteche digitali è il Berkeley Digital Library SunSITE (http://sunsite.berkeley.edu/). Si tratta di un progetto realizzato dalla University of Berkeley volto a favorire progetti di ricerca nel campo delle biblioteche digitali attraverso la fornitura di supporto tecnico e logistico. Nell'ambito di questa iniziativa sono state avviate sperimentazioni che vedono coinvolte numerose università, biblioteche e centri di ricerca nordamericani in vari ambiti disciplinari. Il sito, oltre ad avere un archivio delle iniziative in cui è direttamente coinvolto, fornisce anche un repertorio generale di biblioteche digitali all'indirizzo http://sunsite.berkeley.edu/ Collections/ othertext.html. A differenza dei repertori di biblioteche digitali, i meta-cataloghi di testi elettronici forniscono dei veri e propri indici ricercabili di documenti, indipendentemente dalla loro collocazione originaria. Due sono le risorse di questo tipo che occorre menzionare. La prima è The On-Line Books Page, realizzata da Mark Ockerbloom e ospitata dalla University of Pennsylvania (http://onlinebooks.library.upenn.edu/). Questo sito offre un catalogo automatizzato di opere in lingua inglese disponibili gratuitamente in rete. La ricerca può essere effettuata per autore, titolo e soggetto, e fornisce come risultato un elenco di puntatori agli indirizzi originali dei documenti individuati. Oltre al catalogo, il sito contiene (nella sezione intitolata 'Archives') anche un ottimo repertorio di biblioteche e archivi digitali e di progetti settoriali di editoria elettronica presenti su Internet. La seconda, ormai un po' datata, è l'Alex Catalogue of Electronic Texts, curato da Eric Lease Morgan (http://www.infomotions.com/alex/). Più che un semplice repertorio è un vero e proprio archivio indipendente di testi elettronici, dotato di servizi di ricerca bibliografica e di analisi testuale. La ricerca nel catalogo può essere effettuata attraverso le chiavi 'autore' e 'titolo'. Una volta individuato il documento ricercato, è possibile visualizzarne il testo nella copia locale, risalire a quella originale, oppure effettuare ricerche per parola al suo interno o nelle sue concordanze. Un servizio aggiuntivo offerto da Alex è la generazione automatica di versioni PDF ed e-book (da utilizzare con alcuni palm computer come Newton e PalmPilot), che possono essere lette più comodamente off-line. I grandi progetti bibliotecariCome abbiamo detto, l'interesse del mondo bibliotecario tradizionale verso il problema della digitalizzazione è andato crescendo negli ultimi anni. La diffusione della rete Internet e in generale la diffusione delle nuove tecnologie di comunicazione e di archiviazione dell'informazione comincia a porre all'ordine del giorno il problema della 'migrazione' dell'intero patrimonio culturale dell'umanità su supporto digitale. Consapevoli dell'importanza di questa transizione, alcune grandi istituzioni hanno dato vita a grandiosi progetti di digitalizzazione. Per limitarci alle iniziative di maggiore momento, ricordiamo in ambito statunitense la Digital Libraries Initiative (DLI, http://www.dli2.nsf.gov/). Si tratta di un importante programma nazionale di ricerca finanziato congiuntamente dalla National Science Foundation (NSF), dalla Department of Defense Advanced Research Projects Agency (DARPA) e dalla NASA. Scopo dell'iniziativa è lo sviluppo di tecnologie avanzate per raccogliere, archiviare e organizzare l'informazione in formato digitale, e renderla disponibile per la ricerca, il recupero e l'elaborazione attraverso le reti di comunicazione. Vi partecipano numerose università, che hanno avviato altrettanti progetti sperimentali concernenti la creazione di biblioteche digitali multimediali distribuite su rete geografica, l'analisi dei modelli di archiviazione e conservazione delle risorse documentali e la sperimentazione di sistemi di interfaccia per l'utenza. Le collezioni oggetto di sperimentazione sono costituite da testi, immagini, mappe, registrazioni audio, video e spezzoni di film. Nel corso del 1999 il programma DLI è stato rinnovato, portando all'aumento dei progetti in previsione di finanziamento. Legata alla DLI è la rivista telematica D-lib Magazine, sponsorizzata dalla DARPA, un interessante osservatorio sugli sviluppi in corso nel settore delle biblioteche digitali. Con periodicità mensile, D-Lib ospita articoli teorici e tecnici, e aggiorna circa l'andamento dei progetti di ricerca in corso. Il sito Web, il cui indirizzo è http://www.dlib.org/, contiene, oltre all'ultimo numero uscito, anche l'archivio di tutti i numeri precedenti, e una serie di riferimenti a siti e documenti sul tema delle biblioteche digitali. Un programma in parte simile è stato avviato in ambito britannico. Si tratta del progetto eLib (si veda il sito Web http://www.ukoln.ac.uk/ services/ elib/), che, pur avendo una portata più generale (riguarda infatti tutti gli aspetti dell'automazione in campo bibliotecario), ha finanziato varie iniziative rientranti nell'ambito delle biblioteche digitali, tra cui la Internet Library of Early Journals, un archivio digitale di riviste del XVIII e XIX secolo realizzato dalle Università di Birmingham, Leeds, Manchester e Oxford (http://www.bodley.ox.ac.uk/ilej/). Diversi progetti sono stati sostenuti anche dall'Unione Europea, nel contesto dei vari programmi di finanziamento relativi all'automazione bibliotecaria, e in particolare dalla DG XIII che ha dato vita a un programma intitolato Digital Heritage and Cultural Content (http://www.cordis.lu/ ist/ ka3/ digicult/home.html). Dal canto loro, anche alcune grandi biblioteche nazionali si sono attivate in questo senso. Probabilmente l'iniziativa più nota è quella dalla Bibliothèque Nationale de France, che ha avviato un progetto per l'archiviazione elettronica del suo patrimonio librario sin dal 1992. Obiettivo del progetto è la digitalizzazione di centomila testi e trecentomila immagini, che sono consultabili in parte tramite Internet, in parte mediante apposite stazioni di lavoro collocate nel nuovo edificio della biblioteca a Parigi. Un primo risultato sperimentale di questo grandioso progetto è il sito Gallica (http://gallica.bnf.fr/). Si tratta di una banca dati costituita da diverse collezioni di testi e immagini digitalizzate. Attraverso un motore di ricerca è possibile consultare il catalogo e poi accedere ai documenti, che vengono distribuiti in formato PDF (è dunque necessario installare il plug-in Adobe Acrobat Reader). Nella maggior parte dei casi, tuttavia, il file PDF dei testi disponibili attraverso Gallica contiene la scansione delle immagini delle pagine originali, e non il relativo testo elettronico: non è dunque possibile svolgere ricerche o effettuare analisi testuali al suo interno. Un progetto di digitalizzazione di parte del proprio patrimonio è stato intrapreso anche dalla Library of Congress di Washington, che peraltro partecipa attivamente al programma DLI. Il primo risultato dei programmi di digitalizzazione della LC è il già citato progetto American Memory (http://memory.loc.gov/). Si tratta di un archivio di documenti storici, testi, lettere e memorie private, foto, immagini, filmati relativi alla storia del paese dalle sue origini ai giorni nostri. Tutti i documenti, parte dell'enorme patrimonio documentalistico della biblioteca, sono stati digitalizzati in formato SGML per i materiali testuali, JPEG e MPEG per immagini e filmati, e inseriti in un grande archivio multimediale che può essere ricercato secondo vari criteri. Sebbene con un certo ritardo rispetto alle analoghe iniziative statunitensi ed europee, anche in Italia è stato avviato un progetto nazionale per la digitalizzazione del patrimonio culturale testuale. Si tratta del programma quadro Biblioteca Digitale Italiana, promosso e finanziato nel 2001 dalla Direzione generale beni librari e dell'editoria del Ministero per i Beni Culturali. Gli obiettivi di BDI sono quelli di avviare e coordinare progetti di digitalizzazione, principalmente in ambito bibliotecario, ma soprattutto di definire linee guida e documenti di indirizzo in questo settore, al fine di garantire qualità scientifica, affidabilità e sostenibilità economica dei singoli progetti. Per questo è stato costituito un Comitato guida, composto da diversi esperti, che è al lavoro da ormai due anni. Si deve dire che per ora il programma BDI non ha prodotto risultati concreti in nessuno dei due ambiti. I progetti di digitalizzazione avviati al momento sono due: uno riguarda la digitalizzazione in formato immagine e la creazione di metadati per i cataloghi storici manoscritti, nel quale sono coinvolte 29 biblioteche; il secondo, ancora in fase seminale, la digitalizzazione sempre in formato immagine di periodici. Ma su entrambi non poche sono state le voci critiche, anche assai autorevoli. Per quanto riguarda la produzione di documentazione, questa dovrebbe essere disponibile in una apposita sezione del portale culturale Superdante (http://www.superdante.it/), anch'esso promosso dal Ministero. Tuttavia tale sezione è, nel momento in cui scriviamo, vuota (a parte la scritta 'sezione in allestimento') e anche il resto del portale, nonostante gli sforzi e con alcune eccezioni, non brilla certo per qualità e quantità dei contenuti. Le biblioteche digitali in ambito accademicoAccanto ai grandi progetti nazionali e bibliotecari, si colloca una mole ormai ingente di sperimentazioni che nascono in ambito accademico (in particolare nell'area umanistica) e sono gestite da biblioteche universitarie o da centri di ricerca costituiti ad hoc. I fondi documentali realizzati attraverso questa serie di iniziative rispondono a criteri (tematici, temporali, di genere, ecc.) ben definiti e si configurano come l'equivalente digitale delle biblioteche speciali e di ricerca. Oxford Text ArchiveTra i progetti sviluppati presso sedi universitarie e centri di ricerca istituzionali, quello che spicca per prestigio, autorevolezza e tradizione (se di tradizione si può parlare in questo campo) è l'Oxford Text Archive (OTA), realizzato dall'Oxford University Computing Services (OUCS). L'archivio è costituito (nel momento in cui scriviamo) da oltre 2.500 testi elettronici di ambito letterario e saggistico, oltre che da alcune opere di riferimento standard per la lingua inglese (ad esempio il British National Corpus e il Roget Thesaurus). La maggior parte dei titoli sono collocati nell'area culturale anglosassone, ma non mancano testi latini, greci e in altre lingue nazionali (tra cui l'italiano). Gran parte delle risorse dell'OTA provengono da singoli studiosi e centri di ricerca di tutto il mondo, che forniscono a questa importante istituzione le trascrizioni e le edizioni elettroniche effettuate nella loro attività scientifica. Per questo l'archivio è costituito da edizioni altamente qualificate dal punto di vista filologico, che rappresentano una importante risorsa di carattere scientifico, specialmente per la comunità umanistica. I testi sono per la maggior parte codificati in formato SGML o XML, in base alle specifiche TEI. Poiché in molti casi si tratta di opere coperte da diritti di autore, solo una parte dei testi posseduti dall'OTA sono accessibili gratuitamente su Internet. Degli altri, alcuni possono essere ordinati tramite posta normale, fax o e-mail (informazioni e modulo di richiesta sono sul sito Web dell'archivio); i restanti, possono essere consultati e utilizzati presso il centro informatico di Oxford, a cui tuttavia hanno accesso esclusivamente ricercatori e studiosi.
L'accesso alla collezione pubblica dell'OTA si basa su una interfaccia Web particolarmente curata e dotata di interessanti servizi (http://ota.ahds.ac.uk/). In primo luogo è disponibile un catalogo elettronico dei testi che può essere ricercato per autore, genere, lingua, formato e titolo. Una volta individuati i documenti desiderati, l'utente può decidere di effettuare il download dei file selezionati o di accedere a una maschera di ricerca per termini che genera un elenco di concordanze in formato Key Word In Context (KWIC, in cui il termine ricercato viene mostrato nell'ambito di un contesto variabile di parole che lo precedono e lo seguono), da cui poi è possibile accedere all'intero documento. Il sito Web dell'OTA, inoltre, offre una grande quantità di materiali scientifici e di documentazione relativamente agli aspetti tecnici e teorici della digitalizzazione di testi elettronici. Electronic Text CenterL'Electronic Text Center (ETC) ha sede presso la University of Virginia. Si tratta di un centro di ricerca che ha lo scopo di creare archivi di testi elettronici in formato SGML, e di promuovere lo sviluppo e l'applicazione di sistemi di analisi informatizzata dei testi. Tra le varie iniziative, l'ETC ha realizzato una importante biblioteca digitale, che ospita molte migliaia di testi, suddivisi in diverse collezioni. La biblioteca digitale dell'ETC si basa su una tecnologia molto avanzata. I testi sono tutti memorizzati in formato SGML/TEI, in modo da garantire un alto livello scientifico delle basi di dati. La gestione dell'archivio testuale è affidata a un motore di ricerca in grado di interpretare le codifiche SGML. In questo modo è possibile mettere a disposizione degli utenti un sistema di consultazione e di analisi dei testi elettronici che la classica tecnologia Web non sarebbe assolutamente in grado di offrire. Ad esempio, si possono fare ricerche sulla base dati testuale, specificando che la parola cercata deve apparire solo nei titoli di capitolo, o nell'ambito di un discorso diretto. La biblioteca contiene testi in diverse lingue: inglese, francese, tedesco, latino; in collaborazione con la University of Pittsburgh, sono stati resi disponibili anche testi in giapponese, nell'ambito di un progetto denominato Japanese Text Initiative. Tuttavia, solo alcune di queste collezioni sono liberamente consultabili da una rete esterna al campus universitario della Virginia: tra queste la Modern English Collection, con oltre 1.500 titoli, che contiene anche illustrazioni e immagini di parte dei manoscritti; la Middle English Collection; la Special Collection, dedicata ad autori afro-americani; la raccolta British Poetry 1780-1910. Da un paio di anni, infine, l'ETC ha reso disponibile in modo gratuito una vasta collezione di testi nei formati e-book per i software Microsoft Reader e Palm Reader60. Tutte le risorse offerte dallo ETC, oltre a una serie di informazioni scientifiche, sono raggiungibili attraverso il suo sito Web, il cui indirizzo è http://etext.lib.virginia.edu/. Altri progetti accademici internazionaliMolte altre università o centri di ricerca, per la massima parte collocati negli Stati Uniti, hanno realizzato degli archivi di testi elettronici consultabili su Internet. Una istituzione molto importante nell'ambito disciplinare umanistico è il già ricordato Center for Electronic Texts in the Humanities (CETH). Fondato e finanziato dalle Università di Rutgers e Princeton, il CETH ha lo scopo di coordinare le ricerche e gli investimenti nell'utilizzazione dei testi elettronici per la ricerca letteraria e umanistica in generale. L'indirizzo del sito Web del centro è http://scc01.rutgers.edu/ceth/. Tra i progetti sperimentali del CETH, ci sono una serie di applicazioni della codifica SGML/TEI per la produzione di edizioni critiche di manoscritti e testi letterari. Il centro, inoltre, è sede di importanti iniziative di ricerca, e sponsorizza la più autorevole lista di discussione dedicata alla informatica umanistica, Humanist. Fondata nel maggio del 1987 da un ristretto gruppo di studiosi, Humanist raccoglie oggi centinaia di iscritti, tra cui si annoverano i maggiori esperti del settore. Come tutte le liste di discussione, essa svolge un fondamentale ruolo di servizio, sebbene nei suoi dieci anni di vita sia stata affiancata da innumerevoli altri forum, dedicati ad aspetti disciplinari e tematici specifici. Ma soprattutto, in questi anni, la lista Humanist si è trasformata in un seminario interdisciplinare permanente. Tra i suoi membri infatti si è stabilito uno spirito cooperativo e una comunanza intellettuale che ne fanno una vera e propria comunità scientifica virtuale. Per avere informazioni su questa lista consigliamo ai lettori di consultare la pagina Web a essa associata, che contiene tutte le indicazioni per l'iscrizione, oltre a un archivio di tutti i messaggi distribuiti finora (http://www.princeton.edu/~mccarty/humanist/). Molto importante è anche l'Institute for Advanced Technology in the Humanities (IATH), con sede presso la University of Virginia di Charlottesville, un altro tra i maggiori centri di ricerca informatica umanistica nel mondo. Il server Web dello IATH, il cui indirizzo è http://jefferson.village.virginia.edu/, ospita diversi progetti, tra i quali il Rossetti Archive, dedicato al pittore e poeta preraffaellita, nonché una importante rivista culturale pubblicata interamente in formato elettronico sulla quale torneremo in seguito, Postmodern Culture. La Humanities Text Initiative (HTI), con sede presso la University of Michigan, cura una serie di progetti, tra i quali l'American Verse Project, che contiene testi di poeti americani precedenti al 1920. L'indirizzo della HTI è http://www.hti.umich.edu/. Per la letteratura francese è invece di grande importanza il progetto ARTFL (Project for American and French Research on the Treasury of the French Language), supportato dal Centre National de la Recherche Scientifique (CNRS) e dalla University of Chicago. L'archivio permette la consultazione on-line di un database contenente oltre duemila testi sia letterari sia non letterari, sui quali è possibile effettuare ricerche e spogli lessicali (non è invece possibile prelevare i file contenenti i testi), ma l'accesso ai servizi più avanzati è purtroppo riservato a istituzioni che abbiano effettuato una esplicita iscrizione. L'indirizzo web del progetto ARTFL è http://humanities.uchicago.edu/ARTFL/ARTFL.html. Un altro prestigioso progetto in area umanistica è il Perseus Project (http://www.perseus.tufts.edu/). Il progetto, avviato nel 1985, si proponeva di realizzare un'edizione elettronica della letteratura greca. Da allora sono state realizzate due edizioni su CD-ROM, divenute un insostituibile strumento di lavoro nell'ambito degli studi classici, contenenti i testi di quasi tutta la letteratura greca in lingua originale e in traduzione, nonché un archivio di immagini su tutti gli aspetti della cultura dell'antica Grecia. Nel 1995 è stata creata anche una versione su Web del progetto, la Perseus Digital Library. Il sito consente di accedere gratuitamente a tutti i materiali testuali del CD, a una collezione di testi della letteratura latina in latino e in traduzione inglese, alle opere complete del tragediografo rinascimentale inglese Christopher Marlowe, e a vari materiali relativi a Shakespeare. L'individuazione e la consultazione dei singoli testi possono avvenire mediante un motore di ricerca, o un elenco degli autori contenuti in ciascuna collezione, da cui si passa direttamente alla visualizzazione on-line. I testi greci possono essere visualizzati sia nella traslitterazione in alfabeto latino, sia direttamente in alfabeto greco (posto che si abbia un font adeguato: comunque sul sito sono disponibili tutte le istruzioni del caso) sia in traduzione inglese (quest'ultima è disponibile anche per i testi latini). Per i testi greci è anche possibile avere informazioni morfosintattiche e lessicografiche per ogni parola. Insomma, un vero e proprio strumento scientifico, oltre che un prezioso supporto per la didattica. I progetti istituzionali e accademici italianiPer quanto riguarda il panorama italiano, al momento due sono i progetti accademici di biblioteche digitali a carattere nazionale, entrambi per diverse ragioni fermi e per molti versi incompleti.
Il primo è progetto TIL (Testi Italiani in Linea, http://til.scu.uniroma1.it/), coordinato dal CRILet (Centro ricerche Informatica e Letteratura, Dipartimento di studi Filologici Linguistici e Letterari di Roma 'La Sapienza', http://crilet.scu.uniroma1.it/). Si tratta di una biblioteca digitale incentrata sulla tradizione letteraria italiana, articolata in diverse collezioni. I testi, codificati in formato XML/TEI, sono interrogabili mediante una interfaccia Web molto avanzata, in grado di fornire sia all'utente occasionale sia al ricercatore avanzati strumenti di ricerca e di analisi testuale. In particolare sono disponibili i seguenti servizi:
Molti testi presenti nella biblioteca digitale TIL, inoltre, sono corredati da una serie di materiali introduttivi e di contesto, che servono a fornire agli utenti nozioni di base relative alle opere archiviate. L'alta qualità nella scelta dei formati di digitalizzazione e delle infrastrutture tecnologiche (pari a quella dei grandi progetti anglosassoni), tuttavia, non è parimenti riscontrabile nel numero dei testi disponibili (circa 400, non tutti affidabili sul piano della trascrizione) e nella progettazione complessiva dell'interfaccia e dei servizi utente. Problemi dovuti anche alla mancanza di continuità dei finanziamenti, di cui soffrono spesso i progetti di ricerca universitaria. L'altra iniziativa che ricordiamo è il progetto CIBIT (Centro Interuniversitario Biblioteca Italiana Telematica, http://www.humnet.unipi.it/cibit/), che raccoglie undici università. Anche la collezione testuale del CIBIT, costituita da oltre 1.500 titoli, si colloca nell'ambito della tradizione letteraria italiana, ma contiene anche testi di carattere storico, giuridico, politico, filosofico e scientifico. Se la dimensione del patrimonio CIBIT è notevole (ma anche qui l'affidabilità della trascrizione non è sempre certificata), le scelte tecniche e progettuali sono largamente al di sotto degli standard di qualità che ci si aspetterebbe da un progetto scientifico. La biblioteca digitale, infatti, è stata basata sul software di analisi testuale DBT, sviluppato presso l'Istituto di linguistica computazionale di Pisa. Questo sistema permette di effettuare ricerche e concordanze dinamiche, ma è legato a un formato di codifica dei documenti proprietario e privo di sintassi, che consente di segnalare solo alcuni basilari riferimenti testuali. Manca del tutto un sistema di gestione e interrogazione di metadati. L'accesso in rete avveniva mediante un applet Java, che fungeva da front end di interrogazione verso il database testuale remoto. Questa scelta, come già segnalavamo nelle precedenti edizioni, suscitava non poche perplessità, poiché richiedeva la disponibilità di linee piuttosto veloci per evitare lunghe attese in fase di accesso, ed era spesso inaccessibile. A conferma delle nostre perplessità si deve dire che l'accesso pubblico ai testi del CIBIT è sospeso ormai da oltre un anno e che l'architettura basata su DBT è stata definitivamente dismessa. Parte del patrimonio testuale è ora consultabile in formato HTML statico e PDF (e dunque senza alcuna possibilità di ricerca), sul sito Biblioteca Italiana (http://www.bibliotecaitaliana.it/), un progetto nato presso l'unità locale CIBIT dell'Università di Roma 'La Sapienza'. Se allo stato la situazione, non particolarmente brillante, è quella descritta, dobbiamo dire che le due iniziative che abbiamo citato hanno avviato un processo di convergenza che dovrebbe portare a breve alla creazione di una nuova biblioteca digitale, la quale erediterà il nome (e l'indirizzo) di Biblioteca Italiana. Il patrimonio testuale di questo nuovo progetto sarà costituito dalla fusione dei due archivi e tutti i testi saranno codificati in formato XML/TEI. I servizi di accesso si baseranno su un sistema di gestione documenti XML che permetterà sia la lettura sia l'effettuazione di complesse ricerche testuali on-line; inoltre i testi liberi da diritto di autore potranno essere trasferiti dall'utente sul proprio computer in diversi formati61: oltre al formato nativo XML/TEI, saranno disponibili i formati Adobe PDF, Microsoft Reader e OeBPS (Open eBook Publication Structure62). Infine la biblioteca digitale sarà dotata di un complesso e innovativo sistema di gestione di metadati in formato XML, basato sullo standard METS (cfr. http://www.loc.gov/standards/mets/) e su software open source. I progetti non istituzionaliCome abbiamo visto, il tema delle biblioteche digitali è al centro dell'interesse della comunità scientifica internazionale e attira grandi progetti di ricerca e notevoli finanziamenti. Ma in questo settore, come spesso è avvenuto su Internet, le prime iniziative sono nate al di fuori di luoghi istituzionali, per opera del volontariato telematico. Novelli copisti che, nell'era digitale, hanno ripercorso le orme dei monaci medievali, ai quali si deve il salvataggio di molta parte del patrimonio culturale dell'antichità, e dei primi grandi stampatori che, a cavallo tra Quattro e Cinquecento, diedero inizio all'era della stampa. E non è un caso che alcuni di questi progetti abbiano scelto di onorare questa ascendenza, intitolandosi con i nomi di quei lontani maestri: Johannes Gutenberg, Aldo Manuzio. I progetti di questo tipo sono numerosi, con vari livelli di organizzazione, partecipazione, dimensione e attenzione alla qualità scientifica dei testi pubblicati. Ne esamineremo due in particolare: il Project Gutenberg, il capostipite delle biblioteche digitali, e il Progetto Manuzio, dedicato alla lingua italiana. Progetto GutenbergIl Progetto Gutenberg (http://www.gutenberg.net/) è senza dubbio una delle più note e vaste collezioni di testi elettronici presenti su Internet. Non solo: è anche stata la prima. Le sue origini, infatti, risalgono al lontano 1971, quando l'allora giovanissimo Michael Hart ebbe la possibilità di accedere al mainframe Xerox Sigma V della University of Illinois. Hart decise che tanta potenza poteva essere veramente utile solo se fosse stata usata per diffondere il patrimonio culturale dell'umanità al maggior numero di persone possibile. E digitò manualmente al suo terminale il testo della Dichiarazione di indipendenza degli Stati Uniti. Nel giro di pochi anni il progetto Gutenberg, nome scelto da Hart in omaggio all'inventore della stampa, le cui orme stava ripercorrendo, attirò decine e poi centinaia di volontari. Per lungo tempo l'iniziativa ha anche goduto dell'esiguo supporto finanziario e logistico di alcune università, supporto che è venuto a mancare nel dicembre 1996. Nonostante il periodo di difficoltà, Michael Hart non si è perso d'animo; anzi è riuscito a potenziare ulteriormente la sua incredibile creatura. Infatti, accanto al patrimonio testuale in lingua inglese, che costituisce il fondo originario e tuttora portante della biblioteca, recentemente sono state aggiunte trascrizioni da opere in molte altre lingue, tra cui il francese, lo spagnolo e l'italiano. Nel momento in cui scriviamo l'archivio si sta rapidamente avvicinando ai diecimila testi (obiettivo che Hart si è proposto di raggiungere per l'inizio del 2004). Si tratta prevalentemente di testi della letteratura inglese e americana, ma della collezione fanno parte anche testi saggistici, traduzioni di opere non inglesi e, come si accennava, testi in altre lingue. Circa settecento volontari in tutto il mondo collaborano all'incremento con un tasso di circa quaranta nuovi titoli al mese. I testi sono programmaticamente in formato ASCII a sette bit (il cosiddetto Plain Vanilla ASCII). Michael Hart, infatti, ha sempre affermato di volere realizzare una banca dati che potesse essere utilizzata da chiunque, su qualsiasi sistema operativo, e in qualsiasi epoca: tale universalità è a suo avviso garantita solo da questo formato. Lo stesso Hart ha più volte declinato gli inviti a realizzare edizioni scientifiche dei testi. Infatti lo spirito del progetto Gutenberg è di rivolgersi al novantanove per cento degli utenti fornendo loro in maniera del tutto gratuita testi affidabili al novantanove per cento. Come ha più volte affermato, fare un passo ulteriore richiederebbe dei costi che non sono alla portata di un progetto interamente basato sul volontariato, e sarebbe al di fuori degli obiettivi di questa iniziativa. Il sito di riferimento del progetto Gutenberg su Web è all'indirizzo http://www.gutenberg.net/, e contiene il catalogo completo della biblioteca, da cui è possibile ricercare i testi per autore, titolo, soggetto e classificazione LC. Una volta individuati i titoli, è possibile scaricare direttamente i file (compressi nel classico formato zip). Ma il progetto Gutenberg per la sua notorietà è replicato su moltissimi server FTP, e viene anche distribuito su CD-ROM dalla Walnut Creek. Al progetto Gutenberg sono anche dedicati una mail list e un newsgroup, denominato bit.listserv.gutenberg, tramite i quali si possono avere informazioni sui titoli inseriti nella biblioteca, si può essere aggiornati sulle nuove edizioni, e si possono seguire i dibattiti che intercorrono tra i suoi moltissimi collaboratori. Progetto ManuzioIl Progetto Manuzio è la prima e più importante collezione di testi in lingua italiana a carattere volontario. Questa iniziativa (che prende il suo nome dal noto stampatore Aldo Manuzio, considerato uno dei massimi tipografi del Rinascimento) è gestita dall'associazione culturale Liber Liber (della quale fanno parte tutti e quattro gli autori del manuale che state leggendo), che coordina il lavoro offerto - a titolo del tutto gratuito e volontario - da numerose persone. Grazie a questo sostegno il progetto ha potuto acquisire in poco tempo numerosi testi, fra cui si trovano grandi classici quali La Divina Commedia, i Promessi sposi, i Malavoglia, ma anche opere rare e introvabili da parte di lettori 'non specialisti'. L'archivio del progetto è costituito da testi in formato ISO Latin 1. Alcuni titoli sono stati codificati anche in formato HTML - e dunque possono essere consultati direttamente on-line tramite un browser Web - e in formato RTF. Allo stato attuale l'archivio comprende circa settecento titoli, tutti disponibili gratuitamente. Le pagine Web dell'associazione Liber Liber, all'indirizzo http://www.liberliber.it/, contengono il catalogo completo dei testi disponibili, insieme a informazioni sull'iniziativa. Il catalogo è organizzato per autori, e offre per ogni titolo una breve scheda informativa nella quale, oltre ai dati bibliografici essenziali e una breve nota di commento, sono indicati l'autore del riversamento, i formati di file disponibili e il livello di affidabilità del testo. Il progetto, infatti, ha l'obiettivo di fornire testi completi e filologicamente corretti, compatibilmente con la natura volontaria del lavoro di edizione. Il progetto Manuzio è nato come biblioteca di classici della letteratura italiana. In questo ambito si colloca il suo fondo principale, che comprende - fra le altre - opere di Dante, Boccaccio, Ariosto, Leopardi, Manzoni, Verga. Ma con il passare degli anni il progetto si è sviluppato in direzione di un modello di biblioteca generalista; sono infatti state accolte anche traduzioni di testi non italiani, alcune opere di saggistica e manualistica tecnica, narrativa fantastica. Alcuni titoli della biblioteca, ancora coperti da diritti d'autore, sono stati donati direttamente da case editrici o da privati che ne possedevano la proprietà intellettuale. Questo esempio di collaborazione tra editoria elettronica ed editoria tradizionale dimostra come i supporti elettronici non debbano essere necessariamente pensati in conflitto con i libri a stampa. Proprio in questi casi, anzi, la libera disponibilità e circolazione dei testi elettronici si trasforma in uno strumento di promozione per il libro stampato e, in ultima analisi, in un potente veicolo di diffusione culturale. Anche per questo motivo abbiamo scelto dal canto nostro di inserire Internet 2004 (come è avvenuto per le precedenti edizioni di questo manuale) fra i titoli del progetto. Altri archivi testualiSulla scia del capostipite Gutenberg, sono nati una serie di progetti simili, dedicati ad altre letterature nazionali. L'omonimo progetto Gutenberg per la letteratura tedesca, ad esempio, si trova all'indirizzo http://www.gutenberg2000.de/. Il progetto Runeberg per le letterature scandinave è uno dei maggiori archivi europei di testi elettronici. Nato come progetto volontario, ora è gestito congiuntamente da Lysator (un centro di ricerca informatico molto importante) e dall'Università di Linköping. Contiene infatti oltre duecento tra classici letterari e testi della letteratura popolare provenienti da Svezia, Norvegia e Danimarca. I testi sono consultabili on-line su World Wide Web all'indirizzo http://www.lysator.liu.se/runeberg/. Il progetto ABU (Association des Bibliophiles Universels, nome anche dell'associazione che lo cura, tratto dal romanzo di Umberto Eco Il pendolo di Foucault) sta realizzando un archivio di testi della letteratura francese. Finora possiede un archivio di 200 classici tra cui opere di Molière, Corneille, Voltaire, Stendhal, Zola, nonché una trascrizione della Chanson de Roland, nel manoscritto di Oxford. ABU, come il progetto Manuzio, sta accogliendo contributi originali donati da autori viventi, e alcune riviste. Il progetto ABU ha una pagina Web all'indirizzo http://abu.cnam.fr/, dalla quale è possibile consultare ed effettuare ricerche on-line sui testi archiviati; la stessa pagina contiene anche un elenco di altre risorse su Internet dedicate alla cultura e alla letteratura francese. Prevalentemente dedicato a testi di ambito religioso, ma con alcune interessanti offerte anche in altri settori, è infine la biblioteca digitale Intratext, all'indirizzo http://www.intratext.com/. La biblioteca, realizzata per iniziativa della società Èulogos, offre strumenti di analisi testuale, incluso un generatore di concordanze KWIC. I testi offerti sono in diverse lingue, italiano incluso. Gli archivi di e-print e la letteratura scientifica on-lineUna trattazione specifica va dedicata al fenomeno degli archivi di e-print. Con questo termine si intendono innanzitutto le copie elettroniche dei cosiddetti preprint, ovvero le versioni preliminari di saggi e articoli scientifici che studiosi e ricercatori mettono a disposizione sul Web prima che essi compaiano su riviste o miscellanee. In questa categoria rientrano anche materiali scientifici inediti o non recensiti e una grande quantità di lavori (report, bozze, relazioni interne, descrizioni di esperimenti) che normalmente non entrano nel circuito della comunicazione scientifica ufficiale, e che tuttavia possono rappresentare fonte di notevole interesse nel lavoro di ricerca. Inoltre, possono naturalmente entrare in archivi di e-print anche le versioni elettroniche, eventualmente aggiornate o modificate, di articoli apparsi su riviste o testi a stampa. Si tratta di una modalità di fare comunicazione scientifica che ha visto una larghissima diffusione negli ultimi anni. Nell'ambito delle scienze 'dure' in particolare, la pratica di pubblicare preprint on-line è ormai il vero canale della comunicazione scientifica operativa, e la pubblicazione su rivista svolge solo il ruolo di sanzione formale e ufficiale di una ricerca63. Sono ormai numerosissimi gli archivi di e-print legati a singole università, associazioni scientifiche, consorzi, enti e istituzioni di ricerca, riviste - il primo e più noto è arXiv (http://arxiv.org/), dedicato a fisica, matematica, scienze dei sistemi e informatica -, per non parlare delle numerosissime pagine Web personali di singoli studiosi. Se i vantaggi introdotti dalla pubblicazione di e-print sono indubitabili, la natura stessa del Web determina alcuni problemi che ne potrebbero limitare la portata: in particolare quello del reperimento dei documenti e della certificazione di autenticità. La presenza di archivi centrali legati a soggetti istituzionali autorevoli e riconoscibili fornisce una soluzione al problema della certificazione, ma resta il problema del reperimento, vista la moltiplicazione delle fonti. Per ovviare a questo problema, nel 1999 a Santa Fe, in occasione di un convegno al quale hanno partecipato i responsabili delle maggiori iniziative di archiviazione digitale di e-prints, è nato il progetto Open Archives Initiative (OAI, http://www.openarchives.org/), che ha sede operativa presso la Cornell University. Obiettivo di OAI è lo sviluppo di una architettura per facilitare la interoperabilità tra archivi di e-print. Alla base di tale architettura si colloca l'Open Archives Metadata Harvesting Protocol (OAI-PMH). Questo protocollo specifica un set di metadati (basato su Dublin Core) con il quale vanno descritti i singoli documenti contenuti in un archivio, e una serie di regole per l'interrogazione remota distribuita e l'interscambio dei record di metadati. L'architettura OAI prevede la presenza di fornitori di dati (i singoli archivi) i quali mettono a disposizione i record di metadati mediante server compatibili con OAI-PMH, e di fornitori di servizi che possono interrogare i metadati di numerosi fornitori di dati e offrire agli utenti strumenti di ricerca integrati64. L'architettura OAI, invece, non prevede esplicitamente che i documenti debbano essere direttamente accessibili on-line, o gratuiti - sebbene di fatto la maggior parte degli archivi che aderiscono al progetto siano liberamente accessibili -, né prescrive il formato con cui essi vanno digitalizzati. Sul sito dell'OAI, nella sezione 'Community', sono elencati tutti gli archivi e tutti i fornitori di servizi di ricerca che aderiscono ufficialmente all'iniziativa: un ottimo punto di partenza per effettuare ricerche di e-prints. Un altro punto di riferimento è l'Open Archives Forum (http://www.oaforum.org/), che si occupa di promuovere il progetto in ambito europeo. Al lettore interessato a esplorare un open archive suggeriamo E-LIS (E-prints in Library and Information Science), che raccoglie numerosi e-prints - alcuni dei quali in italiano - nel settore delle scienze biblioteconomiche e dell'informazione. L'indirizzo di riferimento è http://eprints.rclis.org/. Un approccio diverso è invece alla base del progetto ReaserchIndex, meglio noto come CiteSeer (http://citeseer.nj.nec.com/), sviluppato dai laboratori di ricerca della Nec. Si tratta di un servizio che indicizza (in modo simile a un motore di ricerca) articoli scientifici in formato PDF o PostScript (nella maggior parte pubblicati su riviste o volumi) inviati da autori o editori, e che consente di effettuare ricerche su tale indice. Ma, grazie a un avanzato sistema di analisi del contenuto, per ogni articolo individuato vengono forniti anche un abstract, un elenco di altri articoli di argomento correlato, l'elenco di tutti gli articoli che vengono citati, quelli che lo citano esplicitamente con un breve estratto del contesto di tale citazione, e naturalmente i link per accedere al documento sia nella sua collocazione originale sia in una serie di formati archiviati localmente. Inoltre il sistema consente di effettuare raffinate analisi di rilevanza basate sugli indici di citazione, che sono assai importanti per la valutazione del rilievo scientifico di un articolo (e anche per la valutazione accademica del suo autore). CiteSeer, come la maggior parte degli archivi di e-print, contiene esclusivamente pubblicazioni di argomento scientifico e tecnologico. Note
|
 |
|||||||||
|
|
|
|||||||||
 |
 |
 |
|||||||||
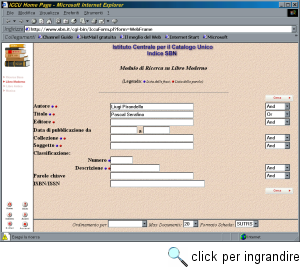
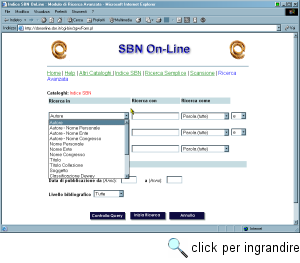
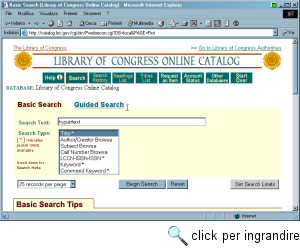
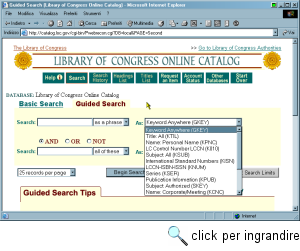
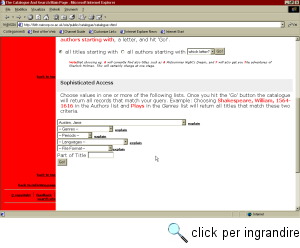
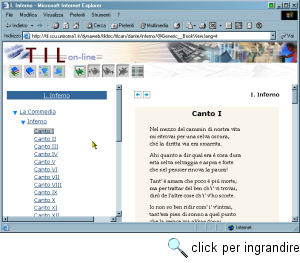



| Inizio pagina |  |
 |